
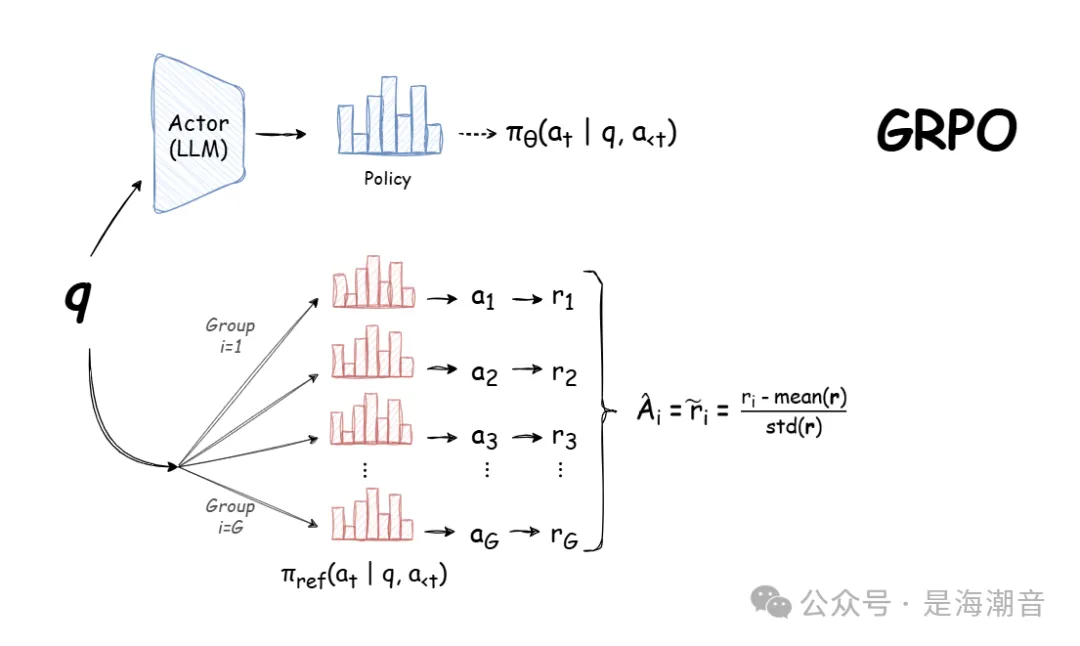
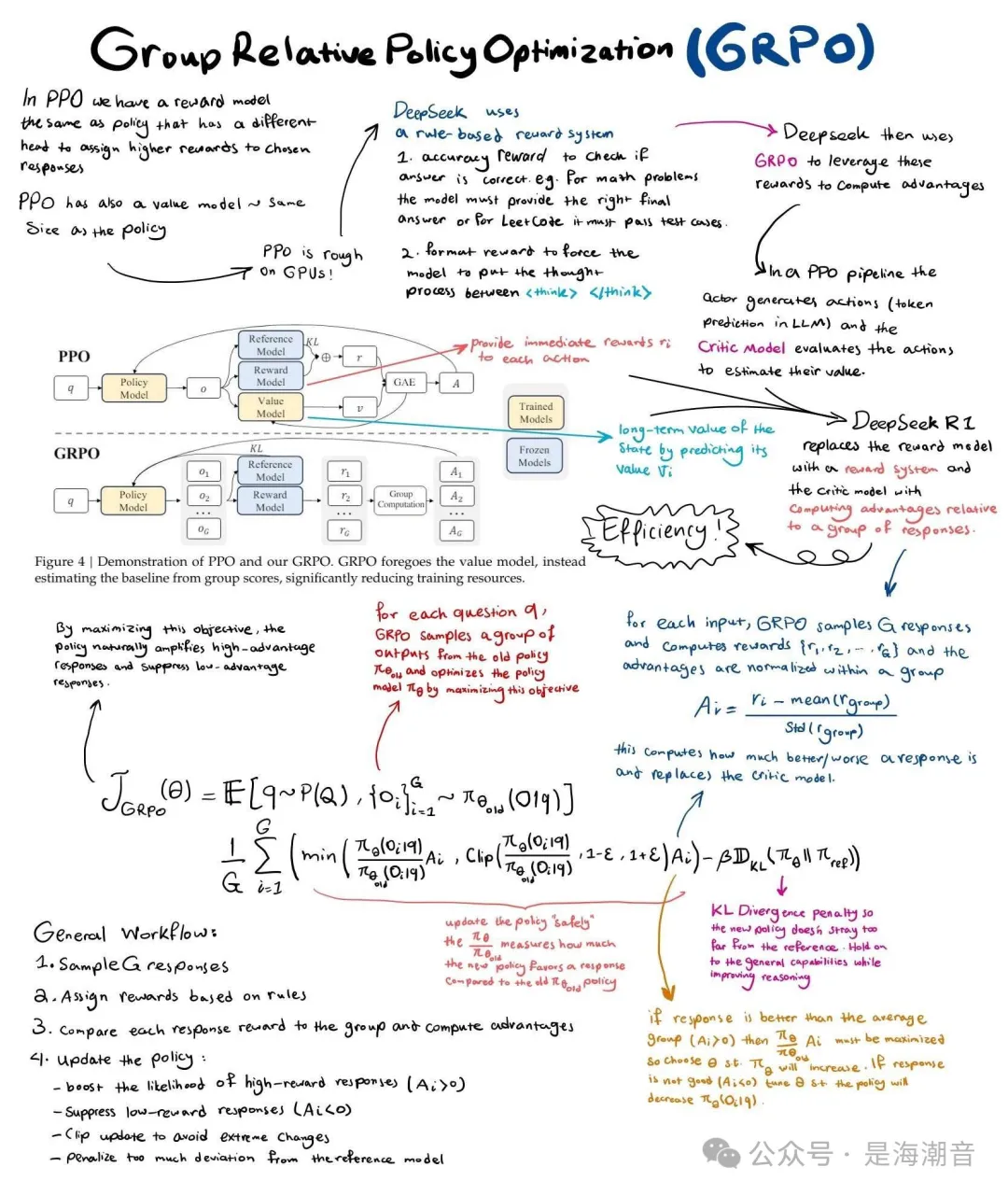
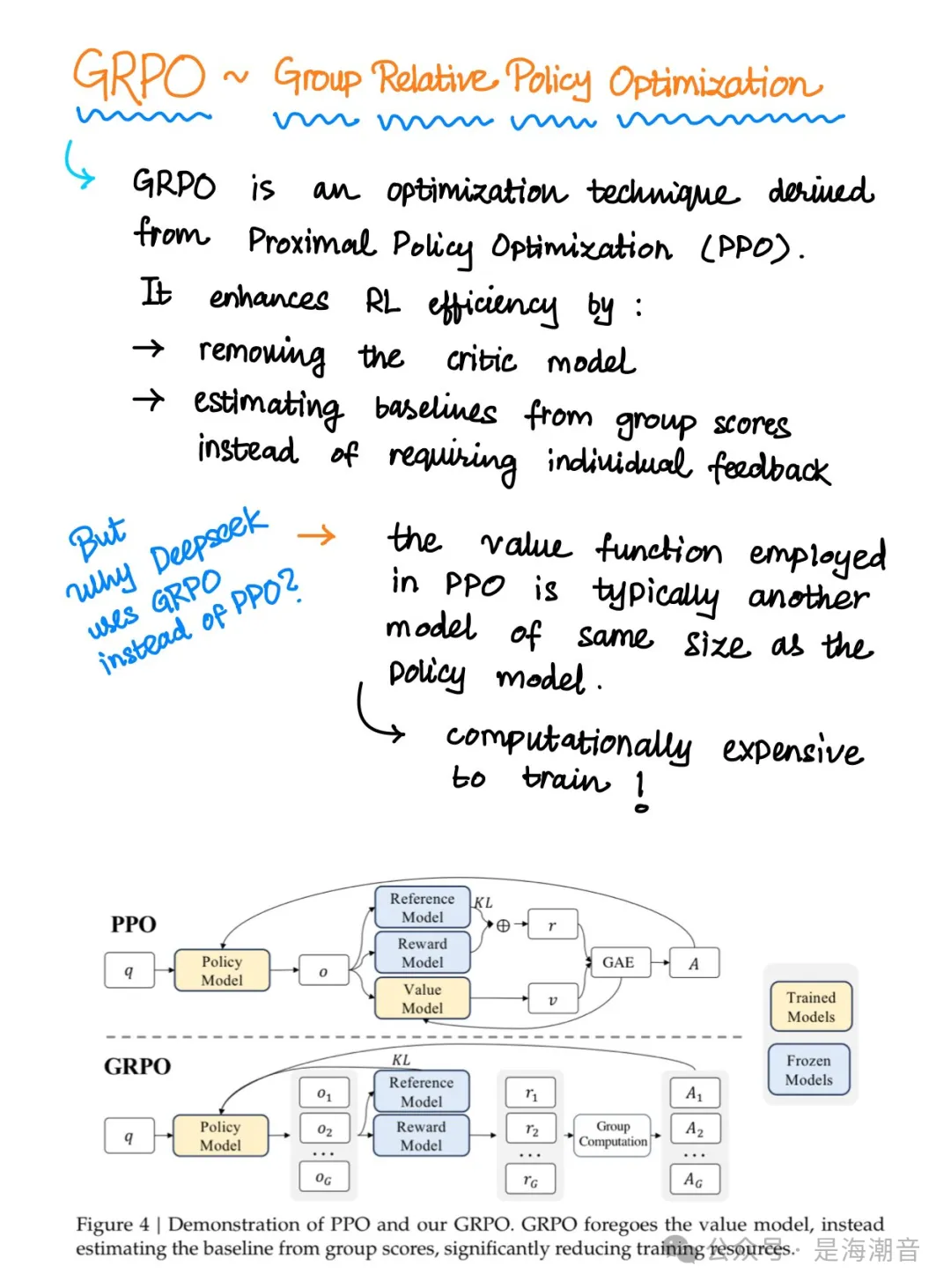
LLM的Post-training: 分为两个阶段。1. SFT,首先使用监督学习,在少量高质量的专家推理数据上微调 LLM; 2. RLHF,因没有足够的human expert reasoning data,需要 RL。GRPO 对 PPO 的改进,其动机是 PPO 需要 4 个大模型,即策略、价值函数、奖励模型和参考模型。GRPO 消除了对价值模型的需求。
为此,GRPO首先为每个查询生成多个响应。然后,在计算advatage时,它将 value 函数替换为样本的奖励,该奖励由同一查询的所有响应的 mean 和 std 标准化。此外,它还将 KL 惩罚移动到损失函数中(RLHF 通常将 KL 惩罚添加到奖励中),从而简化了优势的计算。GRPO 的缺点是它需要为同一 prompt 生成多个响应,因此,如果之前每个 prompt 生成的响应很少,则 GRPO 可能会增加计算时间。
The article is from 是海潮音,Author 是海潮音
本文来自Google DeepMind研究员Jimmy关于PPO & GRPO 可视化介绍
https://yugeten.github.io/posts/2025/01/ppogrpo/
- LLM pre-training and post-training
- DeepSeek’s ultra efficient post-training
- RLHF
- “The RL part”: GRPO
- GRPO Workflow
LLM pre-training and post-training
LLM训练前和训练后
LLM的训练分为pre-training and post-training
- Pre-training: using large scale web data training the model with next token prediction
预训练:使用大型Web数据训练模型,并进行下一个令牌预测
- Post-training: 用来提高模型推理能力,分为两个阶段
Stage 1: SFT (Supervised Finetuning):首先使用监督学习,在少量高质量的专家推理数据上微调 LLM;instruction-following, question-answering and/or chain-of-thoughts。希望在这个训练阶段结束时,模型已经学会了如何模仿专家演示。
Stage 2: RLHF (Reinforcement Learning from Human Feedback):由于没有足够的human expert reasoning data,因此我们需要 RL!RLHF 使用人工反馈来训练奖励模型,然后奖励模型通过 RL 指导 LLM 的学习。
Andrej Karpathy最近对此有个形象的比喻:

Background information / exposition。教科书的核心内容,用于解释概念。当你关注这些信息时,你的大脑正在对这些数据进行训练。这等同于Pre-training,即模型正在阅读互联网并积累背景知识。
Worked problems with solutions。这些是专家解决问题的具体示例。它们是要被模仿的演示。这等同于有监督的微调,即模型在由人类编写的 “ideal responses” 上进行微调。
Practice problems。这些是给学生的提示,通常没有解决方案,但总是有最终答案。通常在每章的末尾有很多很多这样的练习题。它们促使学生通过试错来学习 ,他们必须尝试很多东西才能得到正确答案。这等同于RL。
DeepSeek’s ultra efficient post-training
DeepSeek的超高效训练后
DeepSeek R1 报告中最令人惊讶的一点是,他们的 R1-zero 模型完全跳过了 SFT 部分,直接将 RL 应用于基础模型(DeepSeek V3)。
benefits
- Computational efficiency:跳过post-training的一个阶段可以提高计算效率;
- Open-ended learning:允许模型通过探索“自我进化”推理能力;
- Alignment:避免人工精选的 SFT 数据引入的偏差。
- DeepSeek 还引入 GRPO 来取代 PPO 来提高 RLHF 部分的效率,相较于原来PPO,减少了 critic 模型(通常与Policy模型一样大)的需求,从而将内存和计算开销减少了 ~50%。
PPO vs GRPO
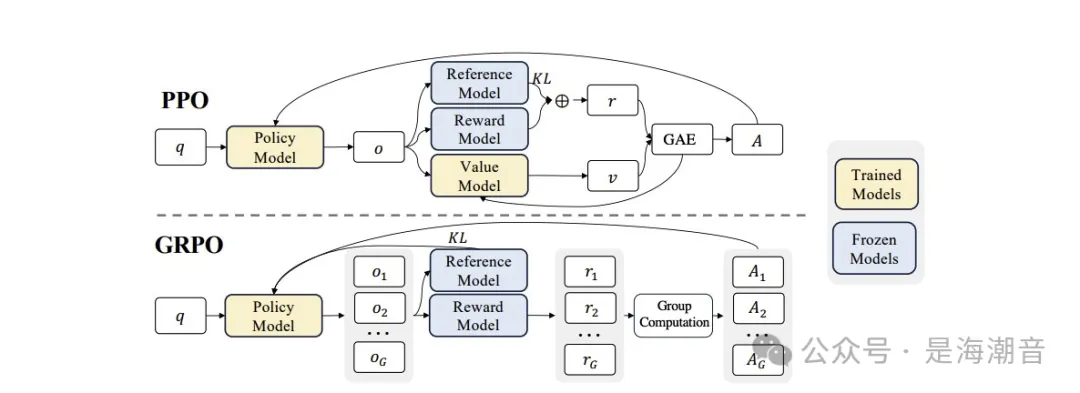
- GRPO 对 PPO 的改进,其动机是 PPO 需要 4 个大模型,即策略、价值函数、奖励模型和参考模型。GRPO 消除了对价值模型的需求。
- 为此,它首先为每个查询生成多个响应。然后,在计算advatage时,它将 value 函数替换为样本的奖励,该奖励由同一查询的所有响应的 mean 和 std 标准化。
- 此外,它还将 KL 惩罚移动到损失函数中(RLHF 通常将 KL 惩罚添加到奖励中),从而简化了优势的计算。
- GRPO 的缺点是它需要为同一 prompt 生成多个响应,因此,如果之前每个 prompt 生成的响应很少,则 GRPO 可能会增加计算时间。
接下来了解下如何实现的:
RLHF
RLHF 的工作流程分解为四个步骤:
Step 1: 对于每个 prompt, 从模型中对多个 responses 进行采样;
Step 2: 人类按质量对这些 outputs 进行排序;
Step 3: 训练 reward model 以预测 human preferences / ranking, given any model responses; 步骤3:训练奖励模型以预测鉴于任何模型响应,人类的偏好 /排名;
Step 4: 使用 RL (e.g. PPO, GRPO) 微调模型以最大化reward model的score
过程相对简单,有两个可学习的部分,即 reward model 和 “the RL”。
现在,让我们深入了解这两部分。
Reward Model
实际上,我们不能让人类对模型的所有输出进行ranking。一种节省成本的方法是让标注人员对 LLM 输出的一小部分进行评分,然后train a model to predict these annotators’ preferences,这就是奖励模型的作用。
奖励模型的目标函数是最小化以下目标

注意,部分响应的奖励始终为 0; 只有对于 LLM 的完整响应,奖励模型才会返回非零标量分数。
“The RL part”: PPO
“RL部分”:PPO
PPO(proximal policy optimization),包含三部分:
PPO ((近端策略优化),包含三部分:
- Policy: 已预先训练/SFT 的 LLM;
- Reward model:一个经过训练和冻结的网络,在对提示做出完全响应的情况下提供标量奖励;
- Critic:也称为值函数,它是一个可学习的网络,它接受对提示的部分响应并预测标量奖励。
具体工作流程:
- Generate responses: LLM 为给定的prompt生成多个response;
- Score responses: reward model 给每个 response 分配 reward;
- Compute advantages: 使用 GAE 计算 advantages (it’s used for training the LLM); 计算优势: 使用gae计算优势(用于训练LLM);
- Optimise policy: 通过优化总目标来更新 LLM;
- Update critic: 训练 value function以更好地预测给定部分响应的奖励。
General Advantage Estimation (GAE)
一般优势估计(GAE)
Our policy is updated to optimise advantage,直观解释,它定义了一个特定的动作at与policy 在状态st决定采取的average action相比 “how much better”。
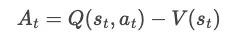
估计这种Advantage有两种主要方法,每种方法各有优劣:
- Monte-Carlo (MC):使用reward of the full trajectory(完整轨迹的奖励)(即完整响应)。由于奖励稀疏,这种方法具有很高的方差——从 LLM 中获取足够的样本来使用 MC 进行优化是昂贵的,但它确实具有低偏差,因为我们可以准确地对奖励进行建模;
- 低偏差:基于完整轨迹的奖励,能够准确捕捉每个部分对最终奖励的贡献。
- 高方差:需要等待整个轨迹生成,奖励稀疏,可能导致训练过程中的结果波动较大。
- Temporal difference (TD):使用 one-step trajectory reward(一步轨迹奖励)(即根据提示测量刚刚生成的单词有多好)。通过这样做,我们可以在token级别上计算奖励,这大大降低了方差,但与此同时,偏差也会增加,因为我们无法准确地预测部分生成的响应的最终奖励。
- 高偏差:基于一步奖励,无法捕捉到整个轨迹的影响,因此预测可能存在误差。
- 低方差:通过实时反馈,训练过程更加稳定。
为了综合这两种方案,提出GAE,balance the bias and variance through a multi-step TD。
但是,之前我们提到过,如果响应不完整,奖励模型将返回 0,当不知道奖励在生成单词之前和之后会如何变化的情况下,我们将如何计算 TD?
因此,我们引入了一个模型来做到这一点,我们称之为 “the critic”。
The critic (value function)
评论家(价值功能)
The critic 受过训练,可以预期仅给出部分状态的最终奖励,以便我们可以计算 TD
Training the critic:训练评论家

critic在训练中对奖励模型的分数进行了简单的 L2 损失。
虽然奖励模型R在 PPO 之前进行了训练并被冻结,尽管R的工作只是预测奖励,但 critic 与 LLM 一起进行了训练。
这是因为 value 函数必须估计给定当前策略的部分响应的奖励。因此,它必须与 LLM 一起更新,以避免其预测过时和不一致。这就是actor-critic in RL。
Back to GAE
回到GAE
通过critic V,我们现在有办法预测部分状态的奖励。我们继续回到GAE,目标函数是computes a multi-step TD。

在 RLHF 中,我们希望最大化这个advantage term,从而最大化 LLM 生成的每个token的reward。
Putting it together – PPO objective
将其放在一起 - PPO目标
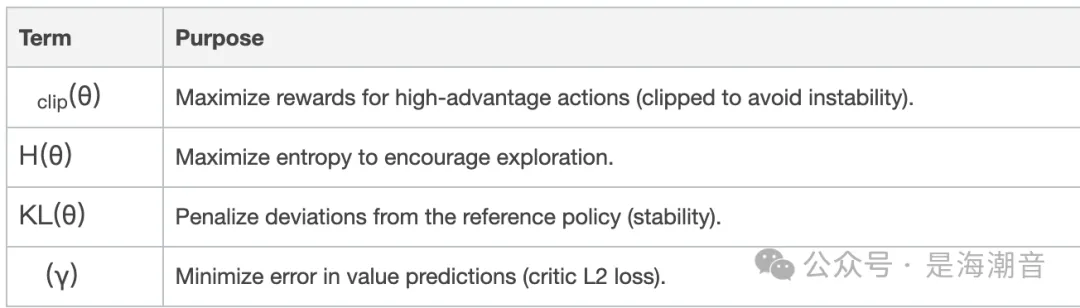
PPO 目标有几个组成部分,即 1) 裁剪的替代目标,2) 熵奖励,3) KL 惩罚。
The clipped surrogate objective
剪裁的代理目标

具体例子:

KL divergence penalty
KL 散度,它可以防止当前策略 thet 偏离我们正在微调thet org
KL 只是通过取序列和批次的平均值来估计的。
# Compute KL divergence between original and current policy/model
logits_orig = original_model(states) # Original model's logits
logits_current = current_model(states) # Current model's logits
probs_orig = F.softmax(logits_orig, dim=-1)
log_probs_orig = F.log_softmax(logits_orig, dim=-1)
log_probs_current = F.log_softmax(logits_current, dim=-1)
kl_div = (probs_orig * (log_probs_orig - log_probs_current)).sum(dim=-1)
kl_penalty = kl_div.mean() # Average over sequence and batch
Entropy bonus
熵奖励通过惩罚低熵来鼓励探索 LLM 的生成
# Compute entropy of current policy
probs_current = F.softmax(logits_current, dim=-1)
log_probs_current = F.log_softmax(logits_current, dim=-1)
entropy = -(probs_current * log_probs_current).sum(dim=-1)
entropy_bonus = entropy.mean() # Average over sequence and batch
Finally, the PPO objective
PPO目标函数:
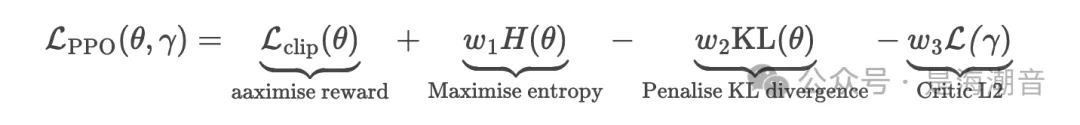
“The RL part”: GRPO
“RL部分”:GRPO
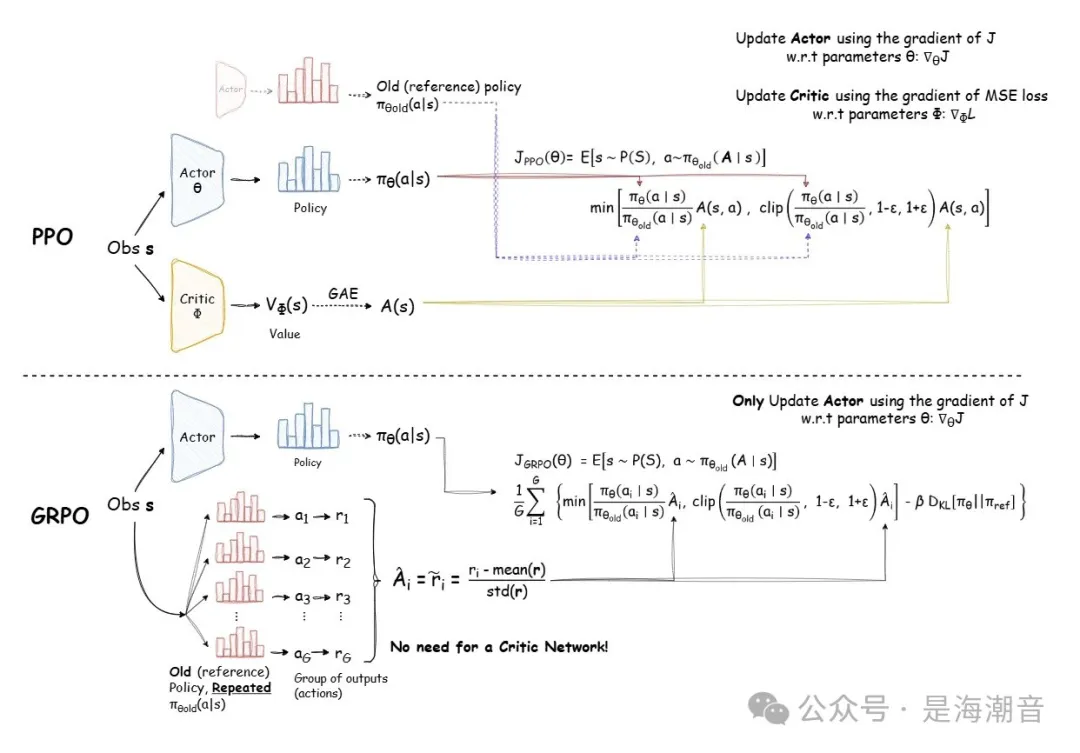
了解PPO 后就容易理解 GRPO ,关键区别在于两种算法如何估计优势 A:GRPO 不像 PPO 那样通过批评者来估计优势,而是使用相同的提示从 LLM 中获取多个样本。

在 GRPO 中,优势近似为响应组中每个响应的标准化奖励。这消除了评论家网络计算每步奖励的需要,更不用说数学的简单性和优雅性了。
The GRPO objective

More thoughts on R1
DeepSeek-R1 的设计反映了 AI 的更广泛趋势:规模和简单性往往胜过巧妙的工程设计。通过无情地偷工减料 — 用规则替换学习的组件、利用大规模并行采样以及锚定到预先训练的基线 — R1 以更少的故障模式实现了 SOTA 结果。它并不优雅,但很有效。
GRPO Workflow
GRPO工作流程
How GRPO works:
- model generates a group of answers
- compute score for each answer
- compute avg score for entire group
- compare each answer score to avg score
- reinforce model to favor higher scores
GRPO的工作方式:
- 模型生成一组答案
- 计算每个答案的分数
- 计算整个组的AVG分数
- 将每个答案得分与AVG分数进行比较
- 增强模型以偏爱更高的分数
Other methods like PPO, use a value function model to do reinforcement learning.
诸如PPO之类的其他方法,使用价值函数模型来进行增强学习。
GRPO does not, which reduces memory and computational overhead when training.
GRPO没有,这在训练时会减少内存和计算开销。
A concrete example of GRPO in action:
GRPO的具体示例:
Query: “What is 2 + 3?”
Step 1: LLM generates three answers.
1. “5”
2. “6”
3. “2 + 3 = 5”
Step 2: Each answer is scored.
1. “5” → 1 points (correct, no reasoning)
2. “6” → 0 points (incorrect)
3. “2 + 3 = 5” → 2 points (correct, w/ reasoning)
Step 3: Compute avg score for entire group.
Avg score = (1 + 0 + 2) / 3 = 1
Step 4: Compare each answer score to avg.
1. “5” → 0 (same as avg)
2. “6” → -1 (below avg)
3. “2 + 3 = 5” → 1 (above avg)
Step 5: Reinforce LLM to favor higher scores.
1. Favor responses like #3 (positive)
2. Maintain responses like #1 (neutral)
3. Avoid responses like #2 (negative)
This process is repeated, allowing the model to learn and improve over time.
How use GRPO in TRL
如何在TRL中使用GRPO
更多图例


文档信息
- 本文作者:huzixia
- 本文链接:https://huzixia.github.io/2025/02/18/ppogrpo/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)