
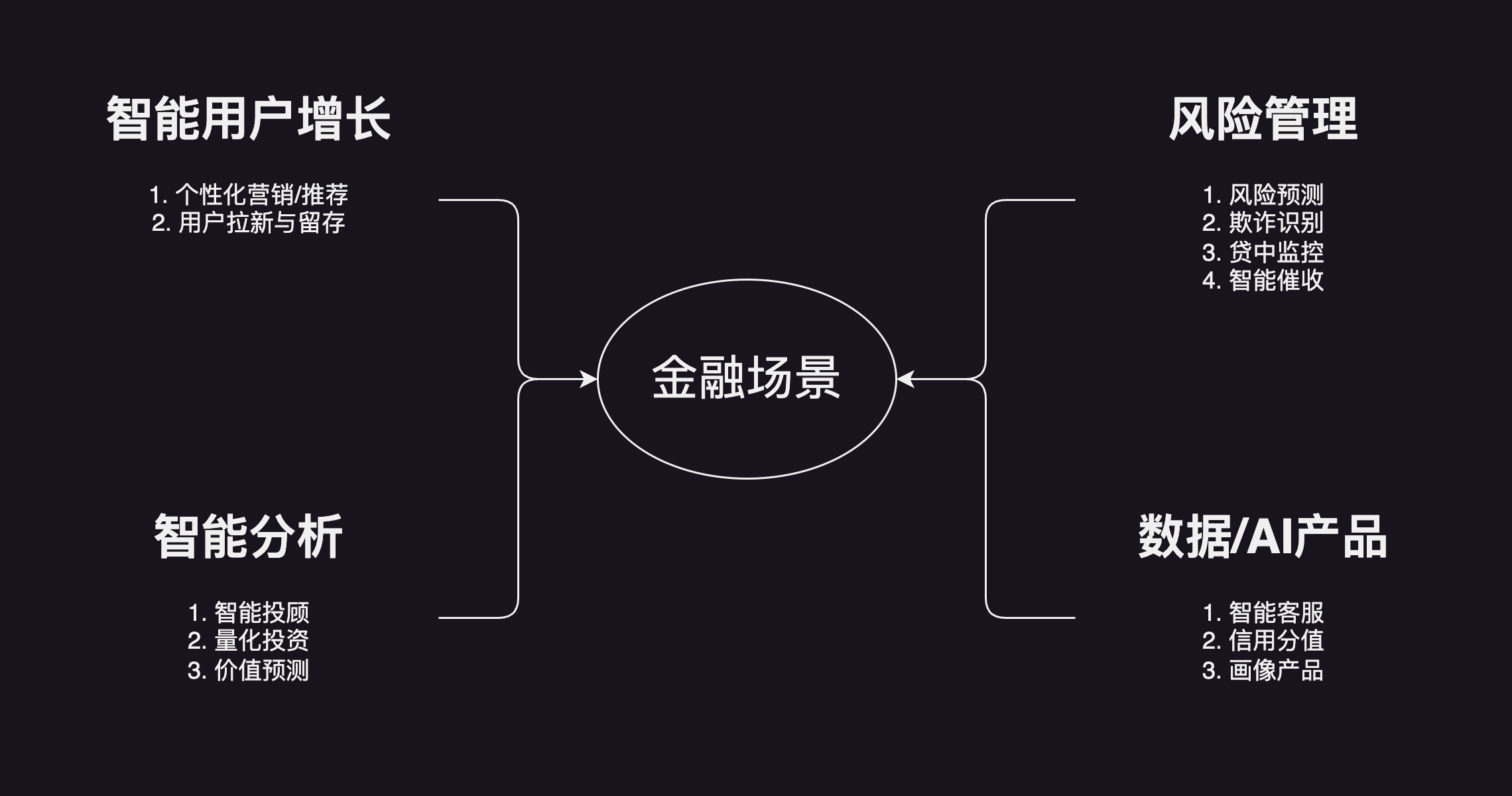
金融领域算法应用场景,主要包括:1. 风险管理(风险预测、欺诈识别、贷中监控、智能催收)2. 数据/AI产品(智能客服、信用分、画像产品)3. 智能分析(智能投顾、量化投资、价值预测)4. 智能用户增长(个性化营销推荐、用户拉新与留存)。
金融场景的增长营销
金融领域算法应用场景
金融领域算法应用场景,主要包括:
- 风险管理
- 风险预测
- 欺诈识别
- 贷中监控
- 智能催收
- 数据/AI产品
- 智能客服
- 信用分
- 画像产品
- 智能分析
- 智能投顾
- 量化投资
- 价值预测
- 智能用户增长
- 个性化营销推荐
- 用户拉新与留存
洞察金融产品的营销爆点:2个目标、3大成效、4大痛点、5大模型、6大方案
2个目标
营销洞察的关键是设定清晰的营销目标。基于产品定位、用户需求、竞争对手、使用习惯,做出正确的营销决策。
比如依托智能推荐引擎,链接借款用户与金融企业,智能匹配目标客户+贷款产品+营销话术+MGM工具,来达到精准营销的目的,并量化营销目标:
一是,定量营销目标:通过用户洞察比用户更懂“用户”,汇聚有真实贷款需求的用户,帮助金融机构找到优质的目标用户,增加客量,通过曝光提升品牌知名度,增加贷款订单销售量。
二是,定性营销目标:通过引入更精准的流量,营销有贷款需求的用户,提高线上运行效率,在深化自己的品牌效益的同时,提升二次转化效率,提高贷款申请的客单数、复贷的转化率。
3大成效
在金融产品营销中,寻找爆点的关键是明确爆点、表达爆点、落地爆点、量化爆点。
第一点,广告投放触达率。
第二点,贷款申请进件率。
第三点,额度授信放款率。
贷款测额是以红包为噱头,基于客户画像与长尾客户进行精准触达和智能展业。
简而言之,实现从测额引流到贷款下单的营销闭环。
爆点让营销更简单,助力金融企业营销获客。
寻找爆点就是找到金融产品的增长因子,通过精准营销形成独家爆品,去洞察“爆点”背后的底层逻辑,解决金融企业的经营效率。
4大痛点
随着金融市场的不断发展,金融行业的竞争也日益激烈,有效开展金融产品营销是金融企业提高竞争力的首要选择。
但是,在金融产品营销的过程中,金融企业寻找“爆点”面临着以下四个痛点:
其一,营销客户缺乏有效洞察:营销客户没有真正的洞察用户需求并为用户创造价值,反而给用户徒增学习成本和操作压力。
因此,只有进行有效的营销洞察,才能识别目标客户,并做出正确的营销决策。
其二,营销活动易受用户抵触:营销活动没有从使用场景出发,规则或门槛让任务完成受到流程受阻,让用户产生逆反心理和抵触情绪。
因此,与用户共情,进行一次有效的沟通,可减少用户对产品的的抵触心理。
其三,营销行为触碰安全问题:营销行为没有重视数据安全问题,导致各大平台掌握用户的大量隐私数据被泄密或倒卖,从而存在欺诈行为或误导风险。
因此,搭建数据安全体系,以便为用户提供个人信息保护或数据安全管理。
其四,营销渠道增加获客成本:营销渠道没有打通各环节,导致同行竞争下,获取客户流量愈发困难,获取客户成本不断飙升。
因此,通过建立渠道营销体系,来精准营销获客,可降低获客成本。
简而言之,用户在体验产品或服务过程中,原本的期望没有得到有效满足,最终导致业绩增长放缓、订单量难以提升、营收不在平衡、利润空间缩减。
5大模型
4P营销理论
营销4P理论是指产品(Product)、价格(Price)、渠道(Place)、促销(Promotion)等基本策略的组合:
产品:产品是品牌的载体,但产品必须有独特卖点。即把产品的功能诉求放在第一位,可以满足消费者的需求与欲望。
价格:根据不同的市场定位,制定不同的价格策略。产品定价、价格调整是企业根据品牌战略的含金量去制定定价策略
渠道:企业将产品所有权从制造商移转到客户渠道选择的策略。即企业并不直接面对消费者,而是注重经销商的销售网络建立,企业与消费者的联系是通过分销商来进行的。
促销:企业需要制定品牌宣传、整合广告、客户公关与销售推广等运营策略,且策略是根据产品生命周期不断调整的。
4R营销原则
4R营销原则主要包括关联(Relevance)、反应(Reaction)、关系(Relationship)、回报(Return)四个要素:
关联(Relevance):企业需要精准找到与消费者的关联点,提供消费者真正需要的产品或服务。这意味着了解消费者的需求与偏好,确保产品、服务或品牌的价值主张与消费者的实际需求紧密结合,从而提高品牌对消费者的吸引力。
反应(Reaction):企业需要迅速而有效地对市场需求和消费者反馈作出反应,尤其是在消费者需求和市场环境快速变化的今天。灵活且敏捷的反应能力不仅可以提高消费者的满意度,还能帮助企业更好地应对市场变化。
关系(Relationship):企业与消费者之间的关系至关重要。通过建立长期、稳定的互动和信任,企业可以维持客户忠诚度,创造品牌粘性。这包括通过客户服务、会员制度、社交媒体互动等方式,与消费者建立强大的情感连接和信任。
回报(Return):企业需要关注消费者对产品或服务的回报感,即提供给消费者的价值是否能满足或超出预期。企业不仅要从销售中获得利润,更需要考虑如何给消费者带来更多的价值,创造积极的客户体验,进而推动消费者的长期回购和口碑传播。
波特五力模型
波特五力模型是指供应商的议价能力、购买者的议价能力、同行业内的竞争能力、潜在进入者的威胁能力、替代品的替代能力等竞争来源:
供应商的议价能力:供应商通过提高投入要素价格与降低单位价值质量的能力,来影响行业中现有企业的盈利能力与产品竞争力。一般取决于供应商的数量、规模、集中度、材料稀缺性等。
购买者的议价能力:购买者通过压价与要求提供较高的产品或服务质量,来影响行业中现有企业的盈利能力。一般取决于购买者的数量、人数、价格敏感性、是否有替代品等。
同行业内的竞争能力:竞争对手的数量、离开行业的成本、行业增长速度和规模、客户忠诚度、资源整合的威胁。
新进入者的威胁能力:新进入者通过给行业带来新生产、新资源的同时,来获得市场份额,导致行业中现有企业盈利水平降低。一般取决于新进入者的资本需要、品牌溢价、产品差异化、规模经济等。
替代品的替代能力:替代品通过提供具有相似功能的产品,或能被用户接受的替代品,来满足客户相同的需要。一般取决替代品的数量、性能、改变成本、转化成本等。
AISAS消费者行为分析模型
AISAS消费者行为分析模型由A引起注意(Attention)、I提起兴趣(Interest)、S信息搜寻(Search)、A购买行动(Action)、S与人分享(Share)构成:
引起注意:通过自媒体、信息流、竞价、DSP、品牌广告、纸媒等方式,将效果广告触达用户,从而引起用户的注意。
提起兴趣:从效果广告中挖掘出满足用户需求的内容,从而让用户对其感兴趣。
信息搜寻:目标用户对产品有一定的兴趣后就会产生搜索行为,然后去搜索产品的口碑和评价以便进一步的对比。
购买行动:在收集了足够的信息之后,客户对满意的产品,最终做出购买决定,为内容付费或为产品买单。
与人分享:客户购买后通常会在互联网上进行分享,向朋友去推荐产品,以便达到口碑传播效果。
STP市场营销战略模型
STP市场营销战略由S市场细分(Segmenting)、T目标市场(Targeting)和P市场定位(Positioning)构成:
市场细分:营销者通过市场调研,依据消费者的需要和欲望、购买行为和购买习惯等方面的差异,将市场中某一产品或服务进行细分。
目标市场:根据市场细分,选择目标市场,明确企业准备以哪一类产品或服务进入一个或多个细分市场,并达到满足某种需求的目的。
市场定位:根据目标市场上同类产品竞争状况,或顾客对该产品的重视程度,对关键特征及卖点进行包装,来获得顾客认同,并明确竞争地位。
以金融企业的STP营销为例,首先根据不同用户的金融服务需求,去寻找合理的金融市场,并将金融市场细分为贷款、理财、货币、基金、债券等子市场,对若干子市场确定有效的细分标准。
然后,选择其中一个或多个细分金融市场,去评估每个细分市场的机会点,进而选择目标市场。
最后,针对每个目标细分市场可能的定位,选择差异化、最合适的定位作为金融产品规划的战略方向。
6大方案
从爆品功能、爆品产品到爆品平台,金融企业都是以功能点作为产品“爆点”,在多场景下触达不同的营销策略,主要有以下6大营销方案:
KOL营销
通过行业KOL聚集有共同兴趣爱好的人,以兴趣爱好作为私域流量的“爆点”,实现规模效应,以小众用户影响到大众群体,进而达到口碑曝光和品牌扩散的目的。
互动营销
基于互动双方的利益共同点,提供多样化场景营销活动,在互动过程中植入品牌软广作为“爆点”,将用户引流至线上持续互动,达到互助推广的营销效果,或加深对品牌的认识。
MGM营销
通过存量客户的转介绍,实现对新客户的联动式营销,从而获取新的客户。因此老带新可以作为MGM营销的“爆点”,采取老带新的方式去营销客户,即可增信又可提升转化率。
事件营销
借助具有新闻价值、社会影响以及名人效应的热门事件或话题进行营销,通过自媒体资源曝光,捕捉用户的兴趣点作为“爆点”,即找出事件线索,进行商机营销,从而,并达成产品促销的目的。
渠道营销
针对渠道特点定位,采取市场推广、网络营销等手段,利用数据分析调整营销策略,打通全渠道营销触点,以达到在终端提高品牌触达率,进而提升渠道CPA或CPS转化效果。
智能营销
通过数字技术应用到产品营销中,实现智能化、自动化的“爆点”营销,为多场景提供精准的商品推荐、人群匹配等准确决策,以达到精准触达、智能展业的营销创新目的。
以贷款广告智能营销为例,金融企业利用“贷款”标签去定向目标客户,若客户使用百度搜索了“贷款”相关词条,则会智能推荐与贷款相关的票据贴现、数字贷、纳税贷、房抵贷等产品,从而实现贷款广告的精准营销。
贷款符合“期限短、额度小、频率高、放款快”的特点,完整覆盖有贷款诉求的用户群体.因此,贷款就是一个很好的“爆点”。
金融场景下增长营销的应用与思考
金融营销
增长营销
增长的本质
- 为企业创造可以不断前进发展与持续获利的增长能力
- 小步实验、快速试错,找到适合且有效的策略去持续并稳定地驱动增长
增长方法
- 增长构建科学的方式,对营销体系建立后的不断实践
- 基于数据洞察形成有效策略
增长营销与推荐系统、计算广告的关系
- 与推荐模型相关,与广告投放角度不同
经典营销框架
营销框架 [marketing Framework]
- 4P营销策略:
- Product 产品、Price价格、Place 渠道、Promotion 促销
- 4C客户战略:
- Consumer’sneeds 需求、Cost 成本、Communication 沟通、Convenience 便利性
- 4R营销原则:
- Interesting 趣味、Interests 利益、Interaction 互动、Individuality 个性
- 产品市场矩阵:
- 营销策略组合
- 顾客金字塔模型:
- 用户分层理解
- SPIN销售法:
- 营销过程推进
- 6W:
- What-Who-When-Where-Why-How …
经典营销框架 = 认准买家 + 满足需求 + 获得回报 [单向]
营销漏斗:Awareness 感知、Evaluation 评估、 Purchase 购买
PMF模型:Product 产品、Market 市场、Fit 契合点
增长思维及技能
在有数据反馈之后,就可从用户一侧反向传递,把单向的经典营销框架推动到另一个层面,构建双向沟通,典型代表就是近年比较流行的增长思维,比如growth hacking,国内大家也经常提类似的概念,背后的本质是增长思维的构建,核心在于通过小步实验增量测试,通过产品和服务的全流程,让策略传递从供给端到用户需求端,然后营销结果从用户需求端反馈到供给端,及时响应优化调整,这种双向营销的流程就构成了对业务增长的支持。
增长思维:小步实验 + 增量测试
增长营销框架 = 全流程产品服务 + 实验 + 循环 [双向]
增长体系
增长范式AARRR
我们看到一些经典的增长范式,最常见的是AARRR增长范式,也有人称为增长模型。AARRR关注最多的是获客流程,希望通过获取大量匹配的用户,提高用户活跃度,在保证留存率的情况下,促使用户进行口碑的传播,最终获得收入增长,这套增长范式,至少有两点值得借鉴,一是对获客重要性的关注,二是漏斗形式的转化;这个范式对其他范式的增长方法的设定,构成了基础的参考。
以漏斗形式将用户从开始到成功转化的行为路径归结为5个关键步骤
增长范式-AARRR
专注于获客
- 获取用户 Acquisition
- 提高活跃度 Activation
- 提高留存率 Retention
- 自传播 Referral
- 获取收入 Revenue
增长范式RARRA
再之后会看到RARRA范式,更强调留存环节,这个环节体现在,尤其是流量的红利从增量变成存量阶段,关注留存有更多价值产出,怎样把留存的环节做得更好,突显它的优先级,RARRA也就是围绕这个目标成为升级版的增长范式,这些范式其实可以给我们借鉴参考,无论是在新客获取还是老客留存,进行概念上的分层和沉淀,当流量获取之后用户的留存变的越来越重要,把老用户运营好,同时老用户带来更多的新用户,这些视角让用户增长变得更加持续。
从增量时代到存量时代,获得流量后的用户留存变得重要,差异在于优先级考量强调留存
增长范式-RARRA
关注用户留存
- 用户留存 Retention:为用户提供价值,让用户回访
- 用户激活 Activation:新用户在首次启动时看到产品价值
- 用户推荐 Referral:让用户分享、讨论你的产品
- 商业变现 Revenue:一个好的商业模式是可以赚钱的
- 用户拉新 Acquisition:鼓励老用户带来新用户
增长范式Growth Loop
从前面两个范式衍生出一个更有持续性、更有增长迭代的思路范式,就是增长飞轮范式。
我们以亚马逊模型来看,亚马逊当时的成功,从他更广泛的商品选择,更好的购物体验,带来顾客数量的增加,同时也带来更多卖家和流量,从而降低成本,能为用户提供更低的价格,这样一个良性的循环,支持了亚马逊快速的成功,这种飞轮范式在业内其他大厂使用之后也产生非常不错的效果,比如Uber也是类似促成更快的接单过程,来促成刺激更多需求,吸引更多司机,这就能扩大司机服务覆盖的区域,减少用户等待时间,为打车用户提供更优质快捷的服务和更低的价格,这样就不断地转起来。
这个增长范式构成的主要要素,包括促进飞轮一些关键要素的结合,使得这些要素形成循环迭代,他在动作之后产生的输出,这些输出又反馈到输入阶段,再返回到拉新或者增量流量,形成良性循环,带来持续增长,这个增长方式其实在业内大企业和一些项目里发挥了不错的作用。
点-线-面,可持续形成”复利”
增长范式-Growth Loop
- 输入 Input [拉新/留存]
- 行动 Action/Step [动作/步骤]
- 输出 Output [转化/收益]
多方法论模型
我们观察这三个范式,以及其他范式,增长都有一些有效的方法,国内各大厂也提出很多值得参考借鉴和学习的方法论。
多方法论模型
- 阿里: A-1-P-L、F-A-S-T、G-R-0-W模型、T-I-M-E方案
- 京东: 4A、5A、G-0-A-L、D-R-E-A-M模型
- 抖音: T-R-U-S-T模型
- 快手: R-I-S-E模型
- 字节: O-5A-GROW模型
- 腾讯: C-I-T模型
用户行为模型
- AID
- AIDMA
- AISA5
- SIPS
- SICAS
- ISMAS
- ADMAS
- Fogg’s行为模型
- 滑梯模型
客户认知模型
- RFM
- 自定义聚类
- 用户意愿模型
- 用户活跃度模型
- 用户偏好识别模型
运营增长模型
- Cohort模型
- 增长曲线
- 留存曲线
- K因子
- 流失预警模型
- 诱饵、触点与规则模型
行为模型举例AIDA
基于行业特点和业务场景,在营销模型方面有一些本地化设计,让业务本身更清晰化,也为业务带来持续有效的发展,我们在这些案例里面看到几大块,比如增长背后的用户行为、用户认知等,产生客群选择,再结合运营的增长模型,把各种契合点融合进去,带来用户不断地增长。
这个过程,涉及到各领域更深入的模型,举例而言,比如我们看这个行为模型,其实在传统营销方面,大家也提过很多行为模型,因为行为模型对应多个动作,最早的AIDA模型,用户从注意力,到产生兴趣,到最终有意愿行动,这种营销方法无论是传统营销里面卖车或卖大件物品,都会参照的方法,其实我们构建互联网场景下的营销活动也是类似的,互联网场景可以带来数据及时反馈,这些反馈及行为的指向性能够被捕获,变得更加精准和高效。
AIDA法则
- 注意 Attention
- 兴趣 Interest
- 欲望 Desire
- 行动 Action
营销方法设计
- 设计好的开场白或引起客户注意
- 想办法激发客户的兴趣,有时采用“示范”这种方式
- 要客户相信,他想购买这种商品是因为他需要
- 购买决定最好由客户自己做出,推销人员不失时机地帮助,客户确认他的购买动机是正确的
行为模型举例Fogg
在金融营销场景下用户的行为模型更具有挑战性,金融决策背后通常有很长的链路,也有很高的成本,所以,如何让用户采取行动,需要考虑很多关键因素。
以金融场景下的理财行为来看,若参考Fogg模型,其实可解构成用户意愿和用户能力两个维度,我们在构建增长模型时,希望用户中有意愿又有能力的人,尽可能去理财,同时对这条可能有困难的曲线,涵盖各种用户,通过定制各种营销方案让用户选择合适的产品,最终能匹配用户本身的服务体验,最终带来用户持续不断地对平台信任和源源不断地增长。
可以看到,增长是“有效方法、有效模型”接入可落地的应用。显然,增长要结合目标的逐个环节去达成。
Fogg行为模型,曲线代表用户是否愿意采取某个行为的阈值,取决于两个因素:
- 用户动机的强弱
- 采取行动的能力,即完成这个行动的难易程度
- 两个关键因素:能在多大程度上激发用户采取你希望他们采取的行动,以及用户收到触发物后付诸行动的难度
以金融场景为例
- 理财进阶用户增长
- 用户细分可探索对不同客群的决策因素trigger来让投资的阈值尽量降低,促进有能力和有意愿的用户尽可能转化
增长指标规划
业内提出的围绕增长指标规划的方案,值得参考。以电商场景举例,OSM+UJM+场景化,值得金融营销以及其他营销场景落地参考。
O代表目标,也可以拆解成各种子目标,比如电商场景里面提升GMV为主目标,那子目标可以拆解为提升用户量、提升转化率、提升客单价等,围绕目标实现,设计相应的策略,这些策略可以很多,多层和交叉结合的策略能帮用户持续提升,以及有价值的转化。策略的设计可依据科学方法来度量,评估该策略是否科学,能否达成目标,每个过程都有相应指标,每个过程都需要提出关键指标,有些场景需要不断地磨合提炼才能摸索到最重要最关键的度量指标,实现策略落地,带来价值提升。这些策略的度量,要融入用户整个生命周期,结合场景在指标落地环节参考评估。
举例说明:
OSM+UJM+场景化,战略目标(O): 提升GMV,拆解目标
- 目标1 提升用户基数
- 目标2 提高转化率
- 目标3 提升客单价
目标1: 提升用户基数
- 目标1的策略(S): 培育/拓展高质量渠道,通过线下导流线上公众号、社群推广引流商城以及其他推广渠道、提升用户的激活转化效果。
- 目标1的度量(M): 渠道质量评估(访问、登陆、加购、下单),拉新落地页的跳出、下单转化,新用户的登录、下单转化效果
目标2: 提高转化率
- 目标2的策略(S):
- 提效流量分发: 提升首页分发效率、优化体验
- 产品体验升级: 优化用户下单购买环节流程体验
- 目标2的度量(M): 首页流量位的曝光、点击销量,下单的关键节点(浏览商品详情、加购、提交订单、支付成功)、整体转化率
目标3: 提升客单价
- 目标3的策略(S):
- 运营促销活动: 新会员折扣、拼团商品、活动商品
- 定向商品运营:采用商品组合式销售,增加单次购买金额
- 目标3的度量(M): 用户的留存率、活跃天数、复购率,用户购买的间隔、每单商品数量、商品平均件单价
用户旅程UJM
- 关注公众号
- 授权登录
- 商城首页
- 商品详情
- 加购下单
- 活动触达
- 参与活动
- 再次购买
增长框架归纳
不论金融场景还是整个通用的增长框架,最主要的四个步骤可以总结为目标、策略、指标、方案,增长策略的步骤包含理解业务、建立假设、科学实验,循环迭代;最终通过小步快跑,实现增长目标的达成。
四步骤
- 目标 Goal
- 增长营销的目标是什么
- 策略 Strategy
- 决定好目标方向后制订策略,包括目标客群[Target Audiences]、渠道[Channel]、增长链路[Growth Funnel/Loops]
- 指标 Metrics/Key Results
- 执行策路之前,需要制定衡量策略成功的标准是什么
- 方案 Action plans
- 落地策路的具体方案,增长工具是什么
增长策略步骤
- 理解业务,建立假设,优先排序,科学实验,循环迭代
增长的关键步骤
- 假设:如何发展有针对性的点子
- 优先:如何为点子进行优先排序
- 实验:如何执行、验证你选择的点子
- 分析:用测试得到的结论完善下一组idea
增长营销体系
在达成业务增长的过程中,需要很多工具和方法,在实际工作中,增长营销体系的构建,包含多层,具体包含数据基础层面、应用支撑层面、增长洞察层面、智能运营层面。
- 基础数据:数仓建设,数据治理(采集、校验、质量),计算引擎(实时、离线),存储引擎(数源、特征、meta)
- 应用支撑:指标报表看板,用户画像管理,服务性能监控
- 增长洞察:多维分析,效果分析(归因、漏斗、路径),智能洞察(用户行为、可视化、因果)
- 智能运营:AB实验,客群圈选(识别、扩散、发现),增长策略(全链路、渠道、复盘)
客群圈选
增长客群细分
围绕增长客群本身的一个细分,除了传统方法基于统计学、行为心理,或者客户周期、用户聚类之外,我们更多要思考用户增长的商业目标,如何能更有效地进行客群分层。
用户分层
- Demographic 人口统计学[年龄 地域等]
- Behavioral 行为划分[用户状态 使用频率等]
- Psychographic 心理划分[习惯 方式 个性等]
- RFM 用户价值
- CLTV 用户生命周期
- Cluster Analysis 客群聚类
产品细分
- 产品类别、信息、风险等
STP框架
- Segmentation 分层 + Targeting 定向 + Positioning 定位
面向增长的客群分层步骤
- 商业目标设定
- 确定分层目标
- 识别分层变量和开发假设检验 hypothesis
- 明确客群分层
- 设计研究
- 数据采集
- 分析数据和识别划分
- 验证结果
- 策略开发设计
- 选择定向划分
- 理解分层启示和建议
- 构建策踣实验
- 执行推广计划
- 识别关键环节
- 制定沟通推广计划
- 执行、监控、复盘
面向客群营销的圈选方法
我们所谈论的分层,是围绕策略进行开发设计,以及在策略落地的过程中,支持用户体验的逐步提升,这里的方法,除了传统的基于标签的、基于 dsp 和 dmp 结合的方法之外,更多的在用包括深度模型在内的图模型与图学习融合、注意力机制融合的各种模型方案。
基于标签[Rule-based]
- 标签体系规则定向
基于相似度[5imilarity-based]
- Cosine similarity & Jaccard similarity、LSH
- youtubeDnn
- ItemCF/UserCF
基于经典模型
- LR、MF、RF、PU-learning
- End2End [Dnn/XGBoost]
基于聚类[BIRCH、CURE]、基于社交关系等
融合注意力机制[Attention-based]
- RALM
- AE-UPCP
融合图学习[Graph-based]
- DeepWalk
- Node2vec
- PinSage
- Hubble
客群圈选模型
客群圈选模型,我们也采取了融合方案,包括对面向营销目标的客群圈选,一方面要支持业务客群的快速扩散,这里地业务本身已有高质量的用户群,除此之外,也会做更精准的客群定向,这就要融入前面所说的各种模型,包括基于相似度、基于深度的,结合注意力机制,结合图学习的方法,最终形成可互补式的客群圈选方案。
目标
- 面向营销目标圈选精准客群
- 最大化转化目标、最大化ROI
模型圈选
- 客群识别[指定划分]
- 客群扩散[种子用户]
- 客群发现[探索]
资源分配
- 带约束动态优化
模型流程
- 数据收集
- 样本生成
- 模型训练
- 模型评估
- 模型部署
客群模型迭代
在方案探索过程中,其实有几个阶段,最早使用多个模型分阶段圈选,其实缺点很明显,就是效果不突出,圈选的量级达不到业务需要;后一个阶段,就使用级联的方式,两个模型的目标能够进行融合打分,但很多时候模型结果和预测的目标存在不一致的情况,两个模型目标不一定能达成共同协作;后来,也和业内一些先进方案做了交叉,一方面使用多任务学习进行多目标模型训练,同时加入图和序列的信息在模型当中,构建多目标的图模型。
在这过程中,把之前需要人为设定权重的问题比较好地解决掉了,即按自适应的方式,把客群按照业务的多个目标有效地圈选,并且达成营销增长效果的实现。
多阶段模型
- 思想:多模型独立训练,分别圈选后再组合
- 优势:可解释性强,业务方可自行组合
- 应用:客群挖掘基础方法,回测可信度达
级联模型
- 思想:多模型独立训练,得分融合再圈人
- 优势:不强依赖回测,可以例行部署实现方使
- 应用:非核心浮收挖掘整体效果提升
多目标图模型
- 思想:多目标单模型联合训练,权重融合再圈人
- 优势:端到端方案,利用全部样本一致性强
- 应用:多场景多类客群控据,整体效果提升
| 方式 | 多阶段 | 级联 | 多目标+图/序列 |
|---|---|---|---|
| 方案特点 | 多模型单独训练,分别预测求交 | 多模型单独训练,结果融合统一打分 | 端到端单模型,多目标权重联合优化 |
| 方案优点 | 对多任务独立性和递进性无要求;可以满足对每个任多目标最低效果要求 | 可以例行化部署,实现方便;多个完全独立的目标效果较好 | 可以保证训练和预测空间一致性;单模型方便部署优化 |
| 方案缺点 | 需要人为设定阈值,例行化难;不能精确保证效果,图人精细度差 | 多模型训练和预测空间不一致;多目标不独立可能无法保证一些目标效果 | 需要人为设置多目标之间权重;目标独立情况下多个目标可能互相干扰 |
动态图模型捕捉金融场景的持续变化
在金融场景下特别是金融领域,这种变化特别快速,只用传统模型或者多目标模型,还是存在不及时或不能有效挖掘相应信息的问题及种种bad case,所以,在市场行情变化很快的情况下,用户和物品的交互结构变化也很大的情况下,在图模型基础上改造了一个动态图模型,在原先这种图模型里采样环节、聚合环节和更新环节不适应的地方,进行相应的优化。这样做,金融场景动态变化的目标,在模型中得到很好的体现以及目标达成。
常用Gnn模型的不足
- 采样
- 随机采样策路,容易丢失重要邻居节点
- 缺乏对动态图的支持
- 聚合
- 使用单一类型聚合器进行邻域信息向量聚合,面对不同的任务需要人工筛选合适的聚合方式,且所选择的聚合方式未必适合所有中心节点
- 更新
- 简单相加或者拼接的方式,无法高效学习节点和邻域之间的交耳信息
金融场景物品特征和用户申购偏好快速动态变化,不同市场行情下用户-物品交互图的拓扑结构区别很大,设计构造动态图
- 采样阶段
- 考虑网络拓扑结构的动态性,不同日期分别采样,启发式采样策略减少丢失重要节点的风险
- 聚合阶段
- 多聚合器注意力机制,根据不同任务、不同中心节点,自适应地从不同的角度学习对下游任务有效的邻域信息
- 更新阶段
- 通过图自编码器和特征交叉操作,学习中心节点和邻居节点的交互信息
- 在推荐任务中可以实现高效的用户-物品信息交叉
营销资源运筹分配
除了把用户尽可能圈准之外,营销本身是一个供给侧因素更强的场景,怎样把营销资源有效分配下去,成为重点问题。举例而言,如果只有两类资产,怎样给到不同的用户或者用哪些营销资源给到不同用户,背后都有资产本身的约束,资产不是无限量供应,同时营销资源也不可能无限提供,这时,就是一个待约束的运筹分配问题。
营销资源运筹分配的问题,描述了如何在复杂约束下进行营销资源的最优分配。
ETV预测:
三个客户(u1, u2, u3)及其可能接收的两种营销形式(f1, f2)。每个客户有其预期的转化值(ETV,即Expected Transaction Value)。例如,对于客户u1,f1形式的ETV是510,f2形式的ETV是450。对于客户u3,f1的ETV为500,f2的ETV为300。
资源分配结果:
通过算法进行ETV预测后,通过”Allocation Solving”步骤,系统得出营销形式分配结果。客户u1接受形式f1,u2接受f2,u3接受f1。
整体运筹流程:
整个运筹流程。根据运营设定的ROI(投资回报率)目标和约束条件,系统会实时调整资源的分配情况。这个过程中,资源消耗反馈非常重要,系统会根据客户群体的实时数据优化资源分配。
Uplift分配:
“Uplift分配”方案。这意味着在T=0和T=1的两种不同时间点,每个客户在不同时间段的反应都记录在矩阵中。
通用MCKP营销资源分配:
MCKP(Multiple-choice Knapsack Problem,多重背包问题)的应用。在这个问题中,客户可以被视为不同的背包,每个背包的容量(即营销资源的投放量)有限。每个客户(u1, u2, u3)只能接收1种形式的营销资源,因此我们需要选择最优的分配方案,使得期望的成交价值最大化。
目标是通过优化每个客户对不同营销形式的反应,最大化交付的期望值。公式(1)表示最大化总体的ETV,约束条件(2)到(5)则分别确保客户只能接受一个形式的营销资源、营销资源不超出限制等。
公式解释:
- 目标函数 (1):最大化所有客户对不同营销形式的预期成交价值的总和。
- 约束条件 (2):每个客户只能选择一种形式的营销资源投放。
- 约束条件 (3):确保每个客户只能在一种状态下被投放。
- 约束条件 (4):营销资源总量不能超过给定的约束条件。
- 约束条件 (5):确保客户只能处于投放与未投放两种状态。
总的来说,以上说明了营销资源分配中的复杂性,使用了多种技术和优化方法,如Uplift模型和多重背包问题,来确保资源的最优分配。
LTV增长
正如前面所言,在营销增长方面,与广告推荐和传统推荐不同之处,更核心的点就在
用户LTV的长期增长上面。传统营销或单触点广告营销,大家更关注即时交互,希望能即时转化,而在围绕产品和服务,持续给用户带来价值的增长过程,事实上是和用户多次交互,甚至是全生命周期的全链路交互,这种交互不单看即时转化,考虑更多的就是多状态全链路营销如何转化。我们和业内都有共同的一些思考,它可以构建成一个用户状态的持续的动态的变化,在数学上可把它刻画成马尔可夫决策过程,如何分阶段通过多模型逐步地优化,最终要考虑全链路综合优化这个需求,把单点优化和全局优化结合在一起,这时候才形成增长策略,才是全局的联合优化的最优解。
更大的挑战是:我们构建相应的模型和算法,是希望用户体验最优的情况下,平台的价值也能发挥出来,最终形成长期的可持续的增长模型和算法体系的支撑,这也是一个非常值得探索的大方向。
营销归因
营销归因
除了前面介绍的围绕客群、围绕全生命周期的持续化营销增长支持以外,营销增长另一大需求就是运营、产品、数据同学经常希望解答的因果问题,因果其实是有价值的,就是理解这些用户“如何被转化”“为什么被转化”“为什么没被转化”最后推导出下一次构建怎样的营销方法,让它转化得更好,服务得更好,体验更优。
传统的一些方法是归因分析的方法,包括 5 w 2 h 等,以及一些归因模型、归因方式的选择。这些年大家更多通过AB实验来判断,对于金融场景,AB实验的挑战是有时成本太高。那么,因果推断能够作为一个补充,发挥不少价值。
增长营销中的”因-果”
- 因: 在全链路营销过程时,用户到物品的触点,包括曝光、点击或者其他任何能触达用户的方式
- when: 什么时间
- who: 什么人
- where: 在什么渠道
- what: 做了什么动作
- 果:各环节通过营销动作期望带来转化效果的事件,如转化、复访、防流失等
- 归因模型
- 归因窗口
- 归因方式
- 归因技术
- 归因分析
- 因果推断
- 可解释性
增长因果推断
围绕营销策略以及增长路径,面对归因需求,我们也建立了一些可解释的方法,增长因果推断,在补充AB实验的基础上,通过观察的因果方法,比如倾向抑制因果效应模型等。这些因果推断模型的应用,可以帮助运营了解“为什么这些用户会转化、转化背后的因素是什么、下一次营销策略或增长路径如何调整会更优”。
增长因果推断的不同方法体系,主要分为两大类:实验研究(Experimental Study)和观察研究(Observational Study)。详细的内容结构如下:
1. 实验研究(Experimental Study)
实验研究通过随机对照试验(Randomized Controlled Experiment)进行因果推断,即通过人为的实验设计随机分配处理和对照组,确保组间的差异仅由于处理因素所导致,从而推断出因果关系。由于实验研究的控制性强,因此它是因果推断的黄金标准。
核心方法:
- 随机对照实验(Randomized Controlled Experiment):
- 最经典的实验设计方法,适用于理论上可以完全控制的场景。
2. 观察研究(Observational Study)
在观察研究中,研究者并没有控制参与者的行为或施加任何实验处理,而是通过分析现有数据推断因果关系。观察研究包括准实验研究(Quasi-experimental Research)和异质性处理效应方法(Heterogeneous Treatment Effect Model),适用于无法进行随机实验的场景。
核心方法:
2.1 准实验研究(Quasi-experimental Research)
准实验研究通过模拟实验的设计来推断因果关系。它主要包括以下几种常用方法:
- 倾向分数匹配(Propensity Score Matching):通过匹配具有相似特征的个体,使得处理组与对照组在特征上尽可能相似,从而减少混杂因素的影响。
- 倾向分数加权(Inverse Propensity Weighting, IPW):利用倾向分数对样本加权,调节处理组与对照组的权重,达到平衡样本的目的。
- 双重稳健估计(Doubly Robust Estimator, AIPW):结合了倾向分数匹配和结果模型,进一步提高因果推断的准确性。
- 工具变量法(Instrumental Variable, IV):当存在潜在的未观测变量影响因果关系时,通过工具变量推断因果效应。常见的工具变量方法包括:
- 局部平均处理效应(LATE)
- 2SLS(两阶段最小二乘法)
- DEEPIV(深度工具变量模型)
- 双重稳健IV(Doubly Robust IV)
- 断点回归设计(Regression Discontinuity Design, RDD):适用于政策实施时有明确的断点,如门槛值等,可以通过分析断点附近的数据来推断因果效应。
- 时间序列分析(Time Series Analysis):通过分析时间序列数据的变化来推断因果关系。常见方法包括:
- 合成控制(Synthetic Control)
- 差分中的差分(DID, Difference-in-Differences)
- 中断时间序列(Interrupted Time Series)
2.2 异质性处理效应方法(Heterogeneous Treatment Effect Model)
这类方法适用于推断在不同个体或不同群体下,处理效应的异质性差异,即不同个体对同一处理的反应可能不同。常见方法包括:
- S-learner、T-learner、X-learner、R-learner:这些是通过不同的学习方式来推断异质性处理效应的机器学习方法。
- 广义因果森林(Generalized Causal Forest):通过随机森林来估计个体层面的处理效应。
- 双重机器学习(Double Machine Learning):结合机器学习模型和因果推断技术,进一步提升处理效应估计的准确性。
- Uplift树模型(Uplift Tree Model):专门用于处理营销或推荐场景下的增益模型,分析某一行为对不同客户群体的增益效应。
因果推断领域的各种方法体系,涵盖了实验研究、准实验研究和机器学习等多种技术。实验研究更适用于可控环境,而观察研究则广泛应用于现实场景中的因果推断,结合不同的技术手段提高推断的准确性和实用性。
可解释框架
可解释性,无论从技术方面还是业务需求方面,都存在很大的挑战点,我们通过实验及经验,把它划分为”业务的可解释”和”技术可解释”两大块。
在机器学习模型本身,模型可解释已经在探索中,也有研究paper论文专门提出一系列的综合的可解释方法,但从业务需求来看,由于我们站在增长角度,贴近业务去思考,在业务本身的可解释方面,这种洞察需求会更高一些,我们也构建了相应的支持模板、支持方案,对业务解释能快速见到效果。从技术上来讲,我们把它分成数据可解释、特征可解释和模型可解释三块。
可解释性框架,从业务可解释和技术可解释两个角度对模型的可解释性进行了详细的分类和说明,还有各种模型可解释性方法的分类与实现途径。
1. 业务可解释性
业务可解释性主要是针对业务决策人员所需的模型输出解释,包括以下几个方面:
- 浏览数据:在业务层面上解释模型的输入数据和输出结果,使业务人员能够理解模型的输入源及其涵义。
- 报告生成:生成报告帮助业务人员更好地理解模型的决策。
- 指标体系:从业务角度解释模型的性能表现和各类业务相关的指标。
- 归因诊断:
- 整体解释:解释模型整体的行为和决策逻辑,尤其是如何得出最终的结果。
- 个体解释:解释某个特定用户或样本在模型中的表现,如某个客户的评分是如何被模型决定的。
- 因果推断:判断模型决策中的因果关系。
- Trace Debug:包括数据源诊断、错误数据检测和推荐修正位置信息等,以帮助调试模型和排查错误。
2. 技术可解释性
技术可解释性主要面向技术人员和数据科学家,帮助他们解释和理解模型的内部机制及其行为。包含以下几个方面:
- 数据可解释:数据的相关性、统计性和数据的质量解释。
- 特征重要性:识别哪些输入特征对模型输出产生了最大影响,以及特征的权重等。
- 特征可视化:使用图形化方法对特征和模型的表现进行直观展示,常用方法包括PDP(Partial Dependence Plot)、ICE(Individual Conditional Expectation)、SHAP(SHapley Additive exPlanations)。
- 模型可解释:
- 周边解释:通过外部分析或代理模型来解释黑箱模型的输出,如LIME(Local Interpretable Model-agnostic Explanations)可以解释复杂模型的局部行为。
- 模型可视化:通过决策树、神经网络等可视化方式直观地展示模型的内部逻辑。
- 分层决策树:例如LICE(Local Interpretable Causal Explanations)可以为不同层次的决策过程提供解释。
Map of Explainability Approaches
各种可解释性方法的分类及其对应的模型类型。模型分为透明模型(如线性回归、决策树等)和黑箱模型(如神经网络、支持向量机等),并列出了适用于不同类型模型的解释方法。
核心分类:
- Model types(模型类型):
- 透明模型:易于理解的模型类型,如线性/逻辑回归、决策树、贝叶斯模型等,它们的决策过程相对清晰。
- 黑箱模型:难以直接解释的模型类型,如神经网络、支持向量机等,需要借助特定方法来解释其行为。
- Explainability Categories(可解释性类别):
- Model-Agnostic:与模型无关的解释方法,如局部解释、可视化解释等,适用于不同类型的模型。
- Model-Specific:特定于某种模型的解释方法,如针对神经网络的可视化方法等。
- Explainability Principles(解释原则):
- 基于规则、特征相关性解释、简化方法、相互作用解释等原则,用于解构复杂模型的行为。
- Popular Techniques(流行技术):
- 举例了常用的解释技术,如LIME、SHAP、PDP、ICE、反事实解释等。
在不同场景下如何通过业务和技术层面的解释手段提升模型的可解释性。着重于业务层面的实际应用和技术实现的框架设计,并且详细列出了各种可解释性方法的具体应用和分类,展示了透明模型与黑箱模型的不同解释途径。
数据可解释
数据可解释,就是数据层面,希望快速地通过数据本身体现出来的信息,发现数据背后的有效性、异常性,以及其他因素。这里要用多层次数据本身的一些加工研究的算法方法,快速地发现、探索背的地因素是什么,一个异常值产生的原因是什么。
特征可解释
在特征可解释方面,大家最常问的是“圈选人群的结果”以及“推荐的结果”背后的特征因素是什么,除了这类大家经常用的特征重要性外,我们也形成了一套集成式的解程方法,包括特征变量和预测值这些已经可用的方案。
业务运营问题驱动:
- 影响推荐结果的重要特征是
- 特征值变化如何影响预测结果
- 能否映射成简化规则
- 深度模型局部有哪些重要信息D
集成式解释方法:
- 特征重要性[全局+SHAP]
- PDP&ICE特征变量与预测值关系
- 反事实样例和删除诊断
- 简化规则集输出 [Anchor/inTree]
- 全局代理决策树/GAM
- 局部线性解释LIME/决策树
- 模型蒸馏映射SDT/NBDT
模型可解释
对于深度模型,可解释的难度较大,我们针对深度模型提了一个分层解释方案,我们自己称为“局部聚类的解释方法”,就是分层的对每一层的神经元,来看这一层的神经元做了怎样的决策,那其实这个方案的目的,就是来解释每一层的神经元到底在做怎样的决策信息。我们假设从原始的样本空间到每一层之后,都会进行样本空间的转换,那从先转换的一层的样本空间看,正样本和负样本各自的情况怎样,在正负样本之间,我们用透明化的、容易解释的模型进行一个区分,最后来看每一层的神经网络做了怎样的决策信息。这样更好地理解模型本身,怎么将特征和用户的结果进行了有效的匹配和输出,但图例是以简单的三层神经网络举例,事实上各种复杂的深度神经网络都可做类似工作,进行分层聚类的解释,这也是我们在深度模型可解释方面的一点经验。
问题:多层神经网络的不同隐层学到了什么样的信息?
- 深度神经网络隐层表示经过全连接交叉,难以直观解释每一层学到的信息
- 透明模型表达能力弱,难以拟合整体复杂模型口
Layer-wise局部聚类解释方法 [LICE]
- 对复杂模型各个环节输出决策的特征解释
- 构成先验特征组合优化
- 对每个隐层的emb进行聚类,划分样本空间,使用透明模型进行局部映射关系拟台并提供可解释信息
LICE(Layer-wise局部聚类解释)方法:
LICE是一种用于解释深度神经网络不同层次隐藏信息的技术。它的核心思路是通过局部聚类方法,提取每一层的特征,并提供该层信息的解释。这种方法能够帮助我们理解模型如何通过层层递进学习不同特征。
具体步骤:
- 嵌入层(Embedding Layer):
- 原始特征被输入到嵌入层,嵌入层负责将原始特征转换为神经网络可以处理的表示。
- 隐藏层逐层聚类:
- LICE对每个隐藏层的输出进行聚类处理。图中每一层通过K-means聚类方法,将隐藏单元(如神经元的输出)进行聚类,得到若干个簇,每个簇代表该层中某些相似的神经元激活模式。
- 例如,Layer 1 通过K-means方法聚类后,得到一些不同的簇,这些簇的中心特征可以解释该层学习到的模式。
- 逐层递进解读:
- 对隐藏层的输出进行聚类后,接下来对每一层的聚类结果继续进行K-means聚类。这样可以逐层理解深层神经网络的特征提取过程。
- 例如,Layer 2和Layer 3的聚类结果分别是通过对Layer 1和Layer 2的聚类结果进行进一步处理得到的。每一层的聚类表示了该层隐藏信息的特征。
- 汇聚解释:
- 最后,通过对所有层的聚类结果进行总结,形成对整个模型的全局解释。LICE通过对每一层的解释汇总,给出从浅层到深层的完整模型行为解释。
- 汇聚解释的结果可以帮助我们理解每一层神经元的激活模式是如何逐渐转化为最终决策的。
解释结果:
- 每一层的K-means聚类会产生不同的聚类中心,每个聚类中心代表该层学到的特定特征。
- 最终通过不同层次的特征聚类组合,形成对整个模型学习过程的可视化与解释。
RTA动态出价,为金融行业带来后端转化增效新大招
金融业推行数字化转型已久,许多金融业广告主也已积累了丰富的金融属性数据和较强的数据应用建模能力,并应用于业务推广当中。例如,信贷领域的金融机构可通过风控模型,判断推广受众可被授信的水平;保险行业广告主搭建了LTV(用户全生命周期价值)模型,用于在营销投放中评估人群的重复购保潜力及付费ROI。
广告一直在探索如何更充分地发挥金融机构的一方建模能力,提升广告曝光人群中广告主视角的高价值受众比例。近期,广告新推出了“RTA动态出价”能力,使一方建模不仅能用于定向,还可让投放系统理解人群的差异化价值,动态提升广告在高价值人群中的曝光几率,以便更好地提升后链路转化效率。
RTA动态出价,突破一方建模能力应用局限
此前,广告可通过两种方式,来发挥金融广告主一方建模能力。一是金融广告主将自身建模得到的高质量用户离线生成人群包,直接用于广告定向投放;二是在RTA(Realtime API)推出后,金融广告主接入RTA来实时进行可触达人群的负向排除。
这两种方式本质上都是作用于定向环节,一方建模能力的作用是判断“是否”参与某次竞价,而在进入竞价环节后,则完全由广告侧系统建模来进行出价决策。
“RTA动态出价”则是让金融机构一方建模既判断是否参与竞价,还进一步参与竞价环节,帮助投放系统理解人群的价值差异,实现一方建模应用从“是否出价”到“出价多少”的应用延伸。
在接入“RTA动态出价”能力后,金融广告主一方建模不仅向系统返回是否参与竞价的信息,同时可利用自身建模对实时的曝光请求进行受众价值水平判断,并将结果返回给广告侧。广告根据返回的价值判断,依据价值差异化进行加权出价,高价值受众提高出价,低价值人群降低出价。这将确保广告在广告主视角的高价值人群中获得更有保障的曝光几率,带动转化效率提升。
安全可靠,发挥一方建模优势提升后端转化
对于极度注重数据安全的金融行业来说,“RTA动态出价”可在广告主自己保有数据,满足数据安全性的前提下,让一方建模优势获得更充分的发挥,提升金融广告主从定向到出价全流程的参与度和自主性。
“RTA动态出价”可应用于各类存在受众价值差异判定因素的金融细分领域。如信贷类广告主可在接到曝光请求时,利用自身的风控模型向广告侧返回价值判断信息,在竞价环节对高资质人群提高出价;保险类广告主则可调用付费ROI模型及断缴模型,来判断请求人群的付费后端行为潜质,提升曝光人群中高付费人群比例。
RTA动态出价的应用条件和启用方法
能否发挥“RTA动态出价”的优势,关键在于广告主的一方建模能力能对广告侧下发的曝光请求作出价值判断。此外,还需要广告主自身拥有RTA接口开发的技术能力,并在广告投放端开设RTA广告专用账户。
如果金融行业广告主已满足建模能力需求并完成RTA接入,就可按以下步骤启用RTA动态出价:
广告接入价值评估,重点关注广告侧的数据来源以及加权识别率覆盖情况;
确认广告侧RTA加权等级与模型加权因子的初始映射关系,以及后续的调整思路,双方共同讨论确认测试期内实验方案和实验评估指标;
客户侧根据协议文档完成建模开发;
广告侧打开线上实时回复加权的开关,客户侧开启广告投放,正式进入测试阶段。
“RTA动态出价”是广告应用金融广告主一方建模能力的一次迭代探索,并在测试中展现出明显的高价值人群触达优势和后端转化提升效果。
文档信息
- 本文作者:huzixia
- 本文链接:https://huzixia.github.io/2024/10/08/finance/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)