
文本生成视频,个性化声音,技术栈 Latte + Sambert + Moviepy。这是一个文本转视频的项目,通过输入文本,生成对应的视频。 1. 文字生成动态视频 Latte 2. 文字生成个性化语音 Sambert 3. 视频和语音合成,带有字幕。
#! https://zhuanlan.zhihu.com/p/686856744
🔥 Latte-Sambert-Video
Latte-Sambert-Video
目录: [toc]
1. 项目介绍
这是一个文本转视频的项目,通过输入文本,生成对应的视频。
- 文字生成动态视频,Latte,详见 latte_video.ipynb
- 文字生成个性化语音,Sambert,详见 sambert_audio.ipynb
- 视频和语音合成,带有字幕 ,详见 merge_video.ipynb
2. 效果展示
视频结果在目录 data/result ,以下是一个例子。
https://github.com/HuZixia/Latte-Sambert-Video/assets/38995480/6373543d-33c9-4c9e-a9ad-a3ec49daed61
3. 核心流程
详见 main.py
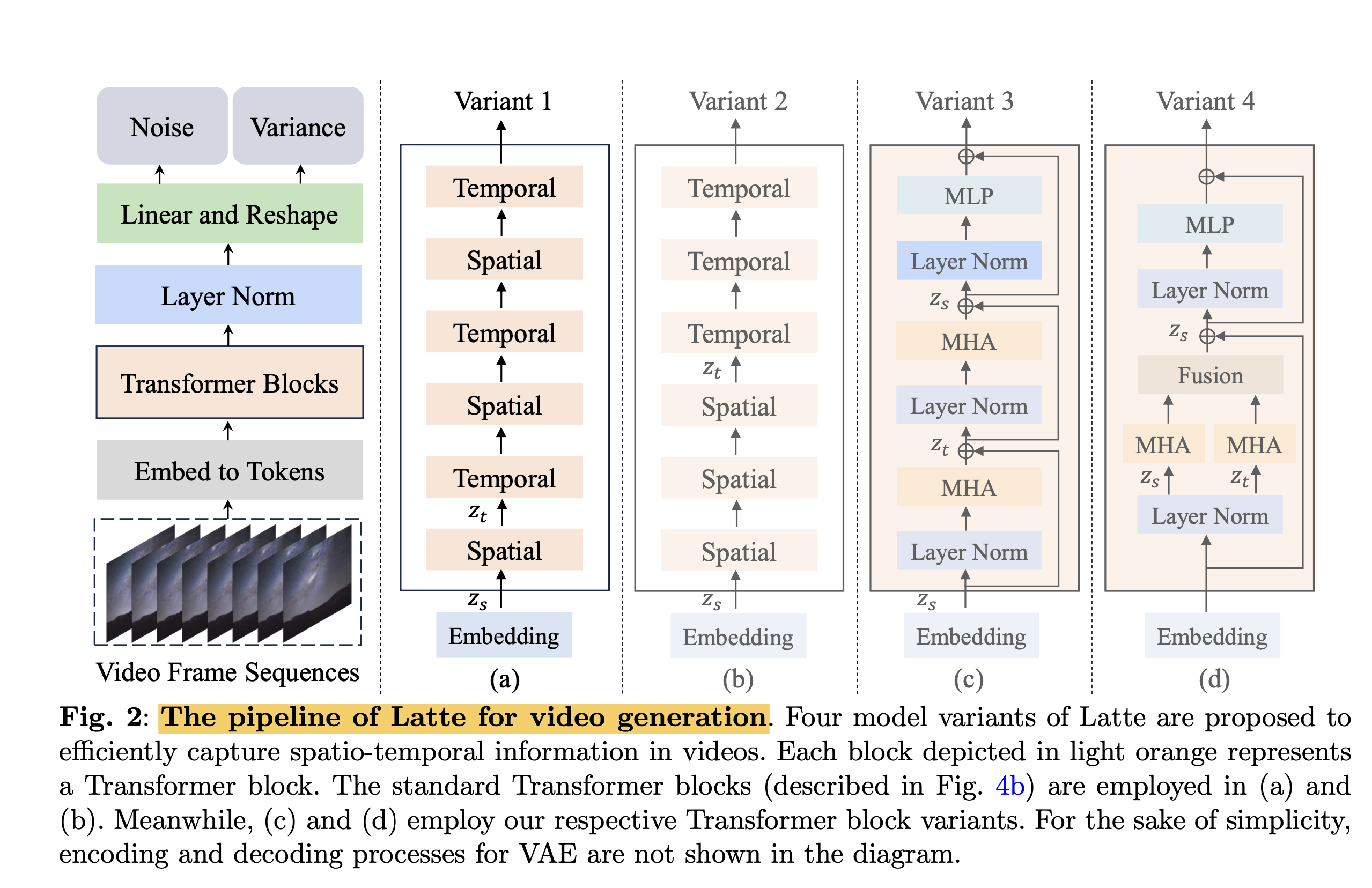
3.1 文字生成动态视频,Latte,详见 latte_video.ipynb
GPU资源:GPU环境,8核 32GB 显存24G,ubuntu22.4-cuda12.1.0-py310-torch2.1.2-tf2.14.0-1.12.0
3.1.1. 安装依赖
# !pip install timm
# !pip install einops
# !pip install omegaconf
# !pip install diffusers==0.24.0
3.1.2. 下载Latte模型
# %cd Latte/models
# !git lfs install
# !git clone https://www.modelscope.cn/AI-ModelScope/Latte.git
3.1.3 修改配置文件
# 修改配置文件 ./Latte/configs/t2v/t2v_sample.yaml
# ckpt: ./models/Latte/t2v.pt
# save_img_path: "./sample_videos/t2v"
# pretrained_model_path: "./models/Latte/t2v_required_models"
# text_prompt: 自定义 prompt 具体内容
3.1.4. 执行Latte生成视频
# %cd ./Latte
# !export CUDA_VISIBLE_DEVICES=0
# !export PYTHONPATH=./
# !python sample/sample_t2v.py --config configs/t2v/t2v_sample.yaml
# GPU资源:GPU环境,8核 32GB 显存24G,ubuntu22.4-cuda12.1.0-py310-torch2.1.2-tf2.14.0-1.12.0
3.1.5. 拷贝Latte生成视频
import shutil
def list_dir(dir_path):
files = []
for file in os.listdir(dir_path):
file_path = os.path.join(dir_path, file)
files.append(file_path)
return files
def copy_file(src_path, dst_path, new_name):
shutil.copy(src_path, os.path.join(dst_path, new_name))
def sample_video(src_dir_path, dst_dir_path):
str = "webv-imageio"
files = list_dir(src_dir_path)
for file in files:
if str in file:
filename = os.path.basename(file)
ext = os.path.splitext(filename)[1]
index = filename.split('_')[1]
new_name = f"{index}.mp4"
copy_file(file, dst_dir_path, new_name)
3.2 文字生成个性化语音,Sambert,详见 sambert_audio.ipynb
3.2.1 准备自己的语音数据,放到 ./data/test_female
3.2.2 安装最新版tts-autolabel
# 运行此代码块安装tts-autolabel
# import sys
# !{sys.executable} -m pip install -U tts-autolabel -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
# 如果由于网络问题安装失败,可以尝试使用国内镜像源, 在Notebook中新建一个代码块,输入如下代码并运行
# !{sys.executable} -m pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
3.2.3 运行TTS-AutoLabel自动标注
# from modelscope.tools import run_auto_label
# input_wav = "./data/test_female/"
# output_data = "./data/output_training_data/"
# ret, report = run_auto_label(input_wav=input_wav, work_dir=output_data, resource_revision="v1.0.7")
3.2.4 基于PTTS-basemodel微调
# 获得标注好的训练数据后,我们进行模型微调
# from modelscope.metainfo import Trainers
# from modelscope.trainers import build_trainer
# from modelscope.utils.audio.audio_utils import TtsTrainType
# pretrained_model_id = 'damo/speech_personal_sambert-hifigan_nsf_tts_zh-cn_pretrain_16k'
# dataset_id = "./data/output_training_data/"
# pretrain_work_dir = "./data/pretrain_work_dir/"
# # 训练信息,用于指定需要训练哪个或哪些模型,这里展示AM和Vocoder模型皆进行训练
# # 目前支持训练:TtsTrainType.TRAIN_TYPE_SAMBERT, TtsTrainType.TRAIN_TYPE_VOC
# # 训练SAMBERT会以模型最新step作为基础进行finetune
# train_info = {
# TtsTrainType.TRAIN_TYPE_SAMBERT: { # 配置训练AM(sambert)模型
# 'train_steps': 202, # 训练多少个step
# 'save_interval_steps': 200, # 每训练多少个step保存一次checkpoint
# 'log_interval': 10 # 每训练多少个step打印一次训练日志
# }
# }
# # 配置训练参数,指定数据集,临时工作目录和train_info
# kwargs = dict(
# model=pretrained_model_id, # 指定要finetune的模型
# model_revision="v1.0.6",
# work_dir=pretrain_work_dir, # 指定临时工作目录
# train_dataset=dataset_id, # 指定数据集id
# train_type=train_info # 指定要训练类型及参数
# )
#
# trainer = build_trainer(Trainers.speech_kantts_trainer,
# default_args=kwargs)
# trainer.train()
3.2.5 个性化语音合成
import os
from modelscope.models.audio.tts import SambertHifigan
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
def personal_audio(pretrain_dir, text_sentences, audio_output):
model_dir = os.path.abspath(pretrain_dir)
custom_infer_abs = {
'voice_name':
'F7',
'am_ckpt':
os.path.join(model_dir, 'tmp_am', 'ckpt'),
'am_config':
os.path.join(model_dir, 'tmp_am', 'config.yaml'),
'voc_ckpt':
os.path.join(model_dir, 'orig_model', 'basemodel_16k', 'hifigan', 'ckpt'),
'voc_config':
os.path.join(model_dir, 'orig_model', 'basemodel_16k', 'hifigan',
'config.yaml'),
'audio_config':
os.path.join(model_dir, 'data', 'audio_config.yaml'),
'se_file':
os.path.join(model_dir, 'data', 'se', 'se.npy')
}
kwargs = {'custom_ckpt': custom_infer_abs}
model_id = SambertHifigan(os.path.join(model_dir, "orig_model"), **kwargs)
inference = pipeline(task=Tasks.text_to_speech, model=model_id)
model_dir = os.path.abspath(audio_output)
# 遍历文本列表,生成并保存音频文件
for i, text in enumerate(text_sentences):
output = inference(input=text)
audio_file = f"{model_dir}/output_{i}.wav"
with open(audio_file, "wb") as f:
f.write(output["output_wav"])
print(f"已保存音频文件: {audio_file}")
3.3 视频和语音合成,带有字幕 ,详见 merge_video.ipynb
from moviepy.editor import VideoFileClip, AudioFileClip, concatenate_videoclips, TextClip, CompositeVideoClip
import os
from textwrap import wrap
def list_dir(dir_path):
files = []
for file in os.listdir(dir_path):
file_path = os.path.join(dir_path, file)
files.append(file_path)
return files
def merge_video(video_dir, audio_dir, output, text_sentences, font='./asserts/SimHei.ttf'):
video_files = sorted(list_dir(video_dir))
audio_files = sorted(list_dir(audio_dir))
final_clips = []
i = 0
chars_per_line = 20
for video_file, audio_file in zip(video_files, audio_files):
video_clip = VideoFileClip(video_file)
audio_clip = AudioFileClip(audio_file)
video_duration = video_clip.duration
audio_duration = audio_clip.duration
wrapped_text = "\n".join(wrap(text_sentences[i], chars_per_line))
txt_clip = TextClip(wrapped_text, fontsize=14, color='white', font=font)
txt_clip = txt_clip.set_position(('center', 'bottom')).set_duration(audio_clip.duration)
i += 1
if video_duration < audio_duration:
n_loops = audio_duration # video_duration + 1
video_clip = video_clip.loop(n=n_loops)
video_clip = video_clip.subclip(0, audio_duration)
video_clip = video_clip.set_audio(audio_clip)
video_clip = CompositeVideoClip([video_clip, txt_clip])
final_clips.append(video_clip)
final_video = concatenate_videoclips(final_clips)
print(output)
final_video.write_videofile(output, codec='libx264', audio_codec='aac')
4. 作者信息
@Author : RedHerring
@微信公众号 : AI Freedom
@知乎 : RedHerring
欢迎关注微信公众号,学习交流 🤓
5. 协议 & 严禁
本仓库代码依照 Apache-2.0 协议开源。
未经许可,严禁商用。
文档信息
- 本文作者:huzixia
- 本文链接:https://huzixia.github.io/2024/04/13/latte/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)