
谢赛宁认为”对于Sora这样的复杂系统,人才第一,数据第二,算力第三,其他都没有什么是不可替代的。” 所以数据的重要性不言而喻,而模型排在第三之后。sora 技术栈 from zero to hero:GAN、AE、DAE、VAE、VQVAE、CLIP、DALL·E、Diffusion Model、LDM、DDPM、Classifier Guided Diffusion、Classifier-Free Guidance、DALL·E 2、Vit、ViViT、MAE、NaViT、Dit 等方面。
#! https://zhuanlan.zhihu.com/p/686141310
Sora 技术栈 解读
目录: [toc]
sora 技术栈
谢赛宁认为”对于Sora这样的复杂系统,人才第一,数据第二,算力第三,其他都没有什么是不可替代的。” 所以数据的重要性不言而喻,而模型排在第三之后。
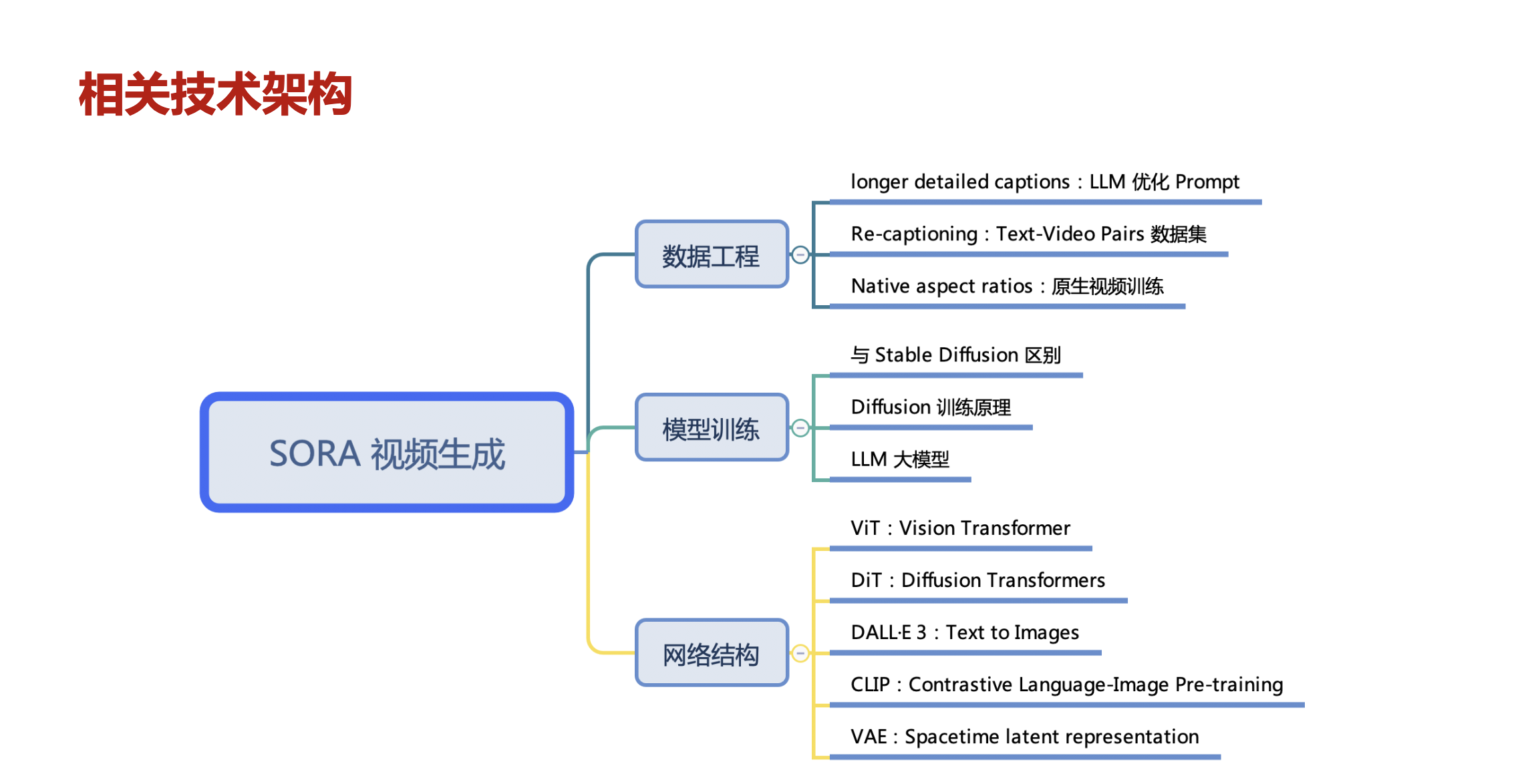
sora视频生成的技术架构,这里主要包括数据工程、模型训练和网络结构等方面。
OpenAI也发布了技术报告,一些关于Sora的剖析:
Sora建立在DiT模型上(Scalable Diffusion Models with Transformers, ICCV 2023)
Sora有用于生成模型的视觉patches(ViT patches用于视频输入)
“视频压缩网络”(可能是VAE的视觉编码器和解码器)
Scaling transformers(Sora已证明diffusion transformers可以有效扩展)
用于训练的1920x1080p视频(无裁剪)
重新标注(OpenAI DALL·E 3)和文本扩展(OpenAI GPT)
sora模型结构,可能表示为:SORA = [VAE encoder + DiT(DDPM) + VAE decoder + CLIP]
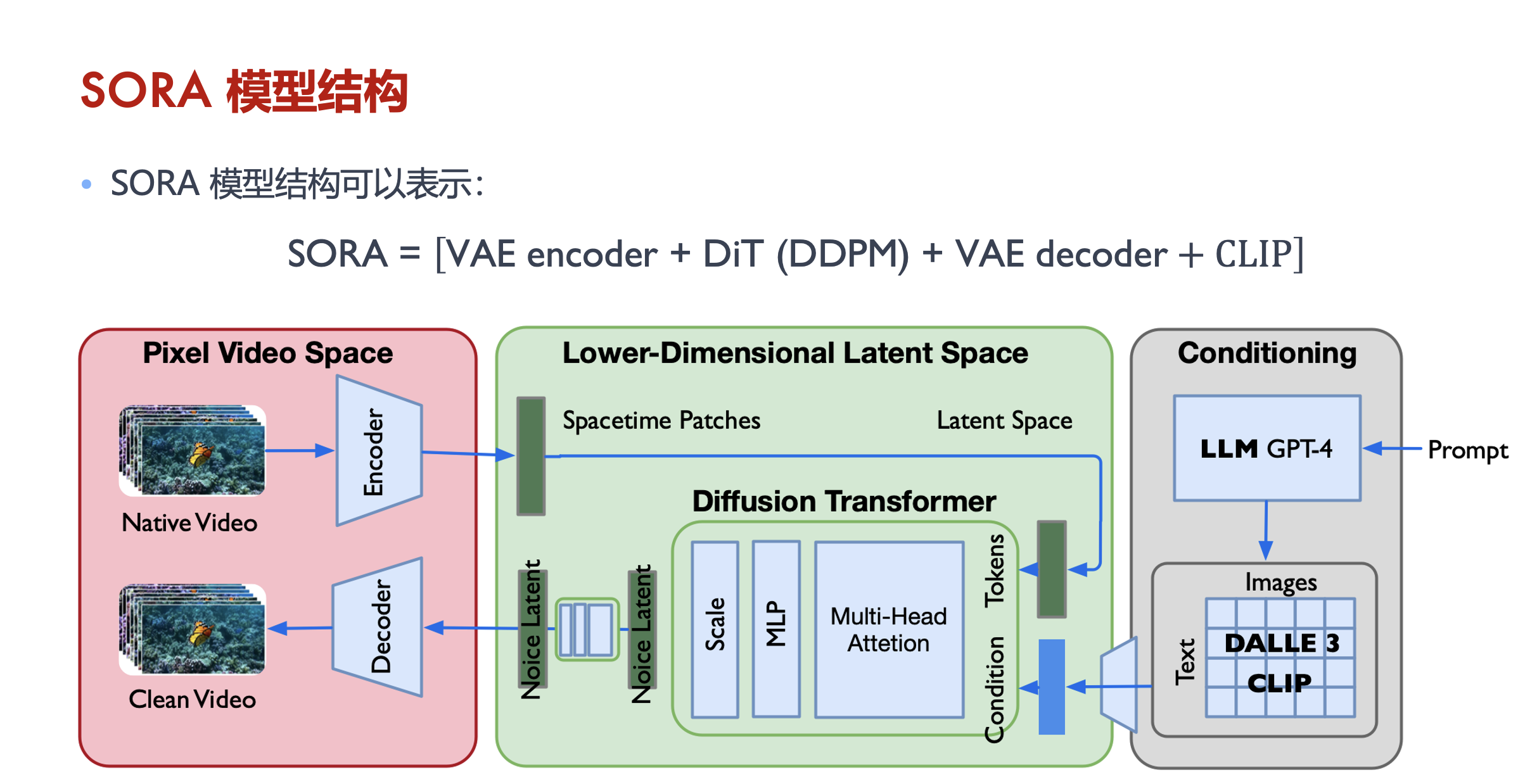
从OpenAI Sora技术报告和Saining Xie的推特可以看出,Sora基于Diffusion Transformer模型。它大量借鉴了DiT、ViT和扩散模型,没有太多花哨的东西。
在Sora之前,不清楚是否可以实现长篇幅一致性。通常,这类模型只能生成几秒钟的256*256视频。“我们从大型语言模型中获得灵感,这些模型通过在互联网规模的数据上训练获得了通用能力。”Sora已经展示了通过可能在互联网规模数据上进行端到端训练,可以实现这种长篇幅一致性。
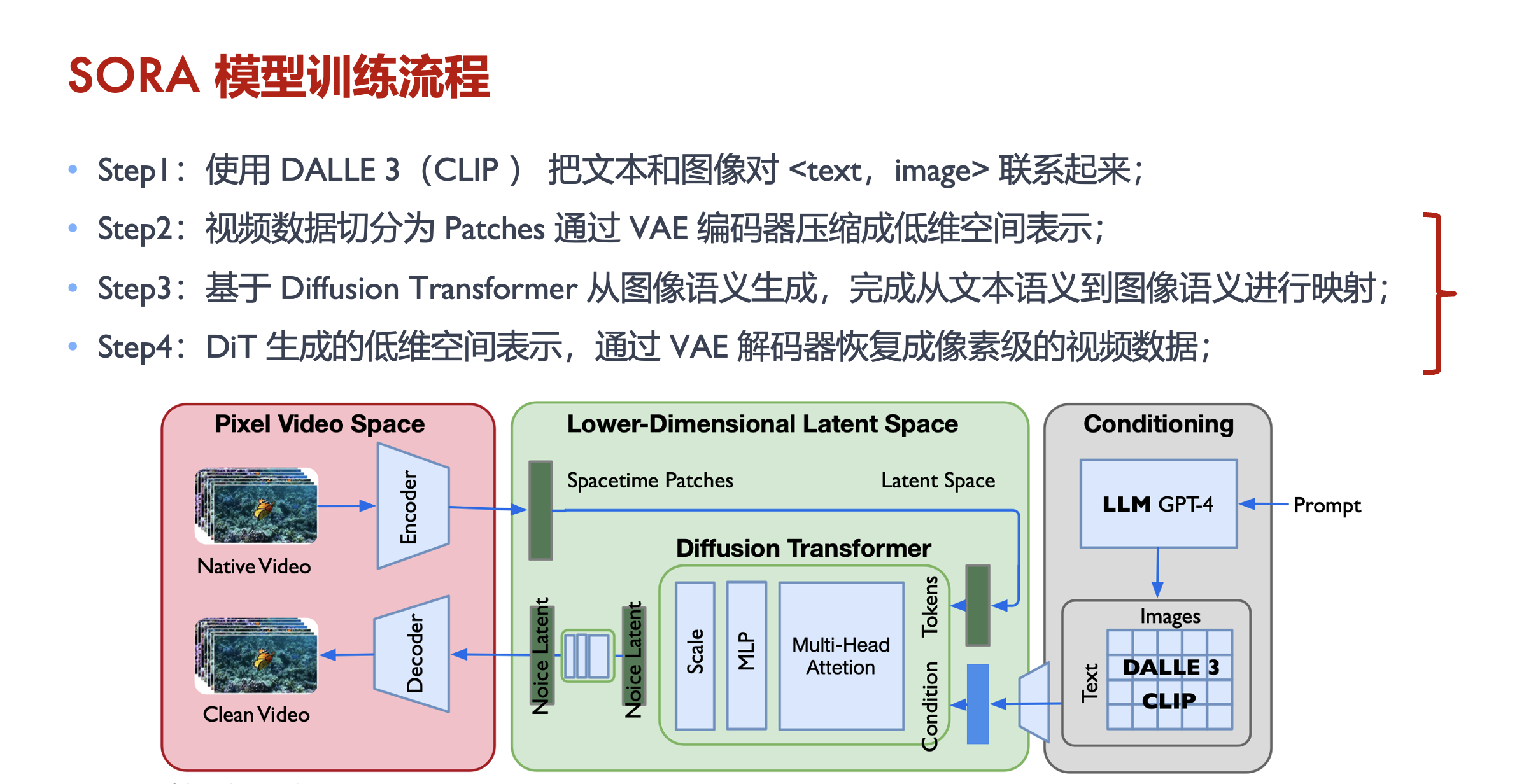
sora模型训练流程:
step1: 使用 DALL·E 3 (CLIP) 把文本和图像对 <text, image> 联系起来
step2: 视频数据切分为 pathces,通过 VAE 编码器压缩成低维空间表示
step3: 基于 Diffusion Transformer 从图像语义生成,完成从文本语义到图像语义进行映射
step4: DiT 生成的低维空间表示,通过 VAE 解码器恢复成像素级的视频数据
- 基于扩散模型 Diffusion Model: runway, pika, midjourney
- 基于 Diffusion Transformer 的模型: sora

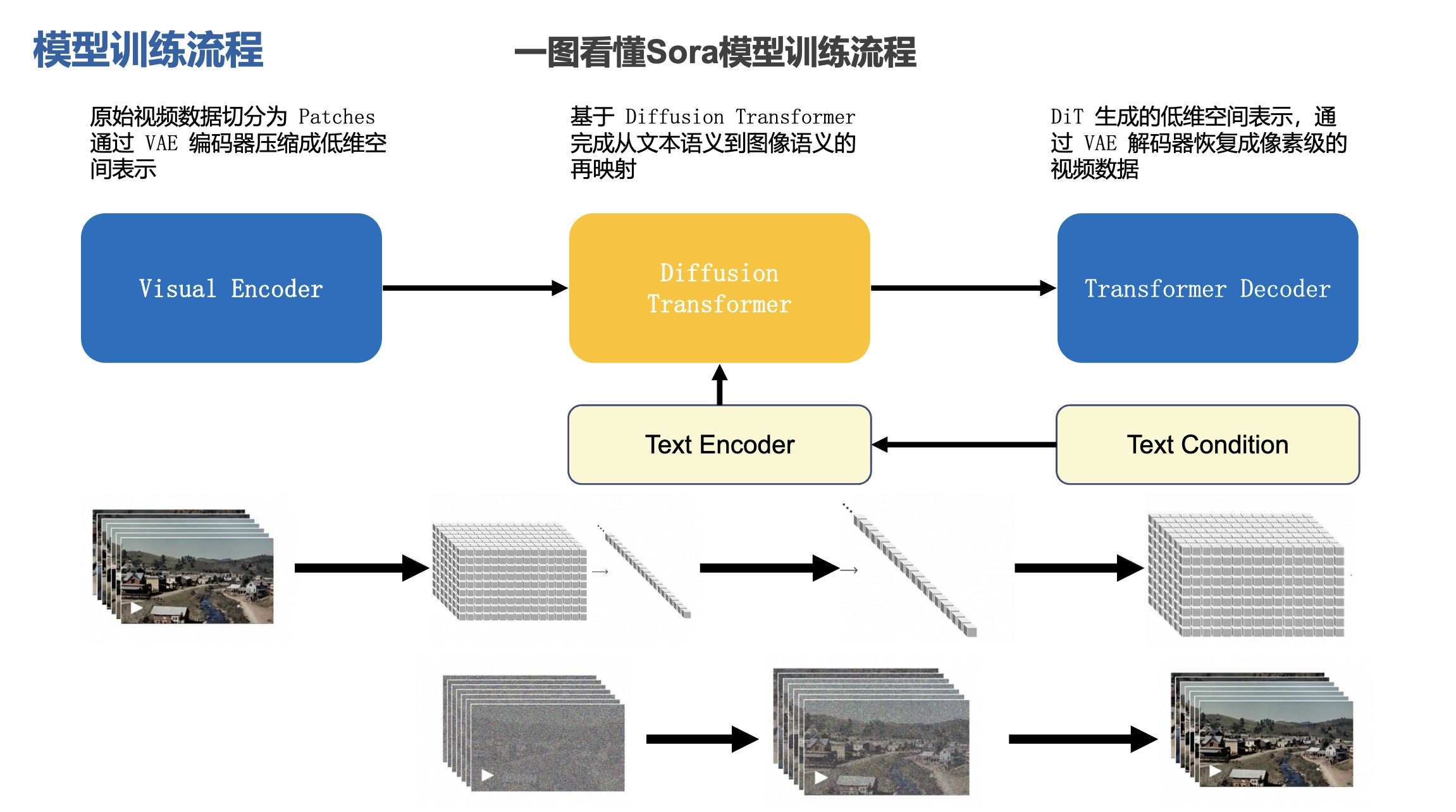
sora模型训练流程:
- 原始视频数据切分为 patches,通过 VAE 编码器压缩成低维空间表示
- 基于 diffusion transformer 完成从文本语义到图像语义的再映射
- DiT 生成的低维空间表示,通过 VAE 解码器恢复成像素级的视频数据
统一表示不同类型的视频数据:
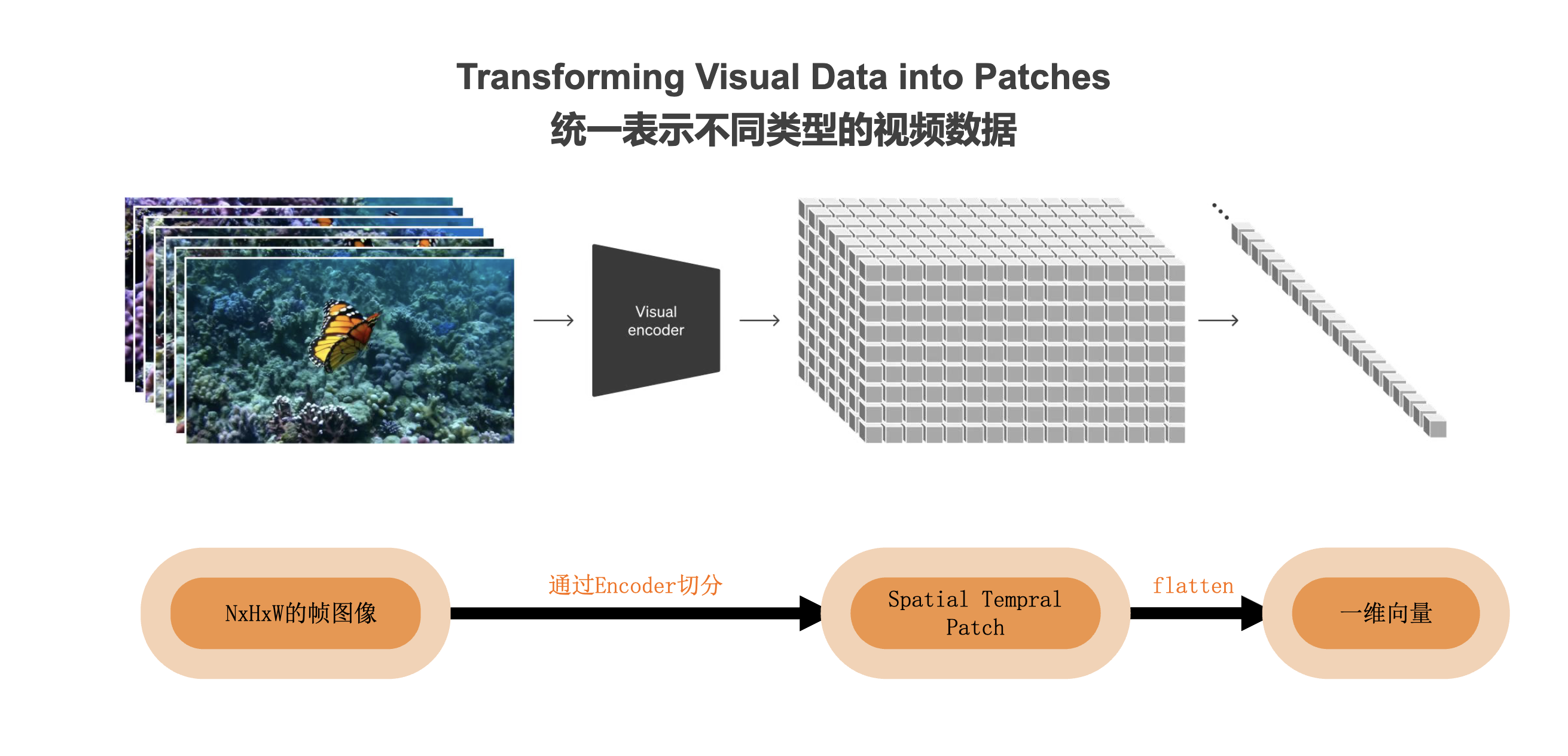
sora from zero to hero
GAN
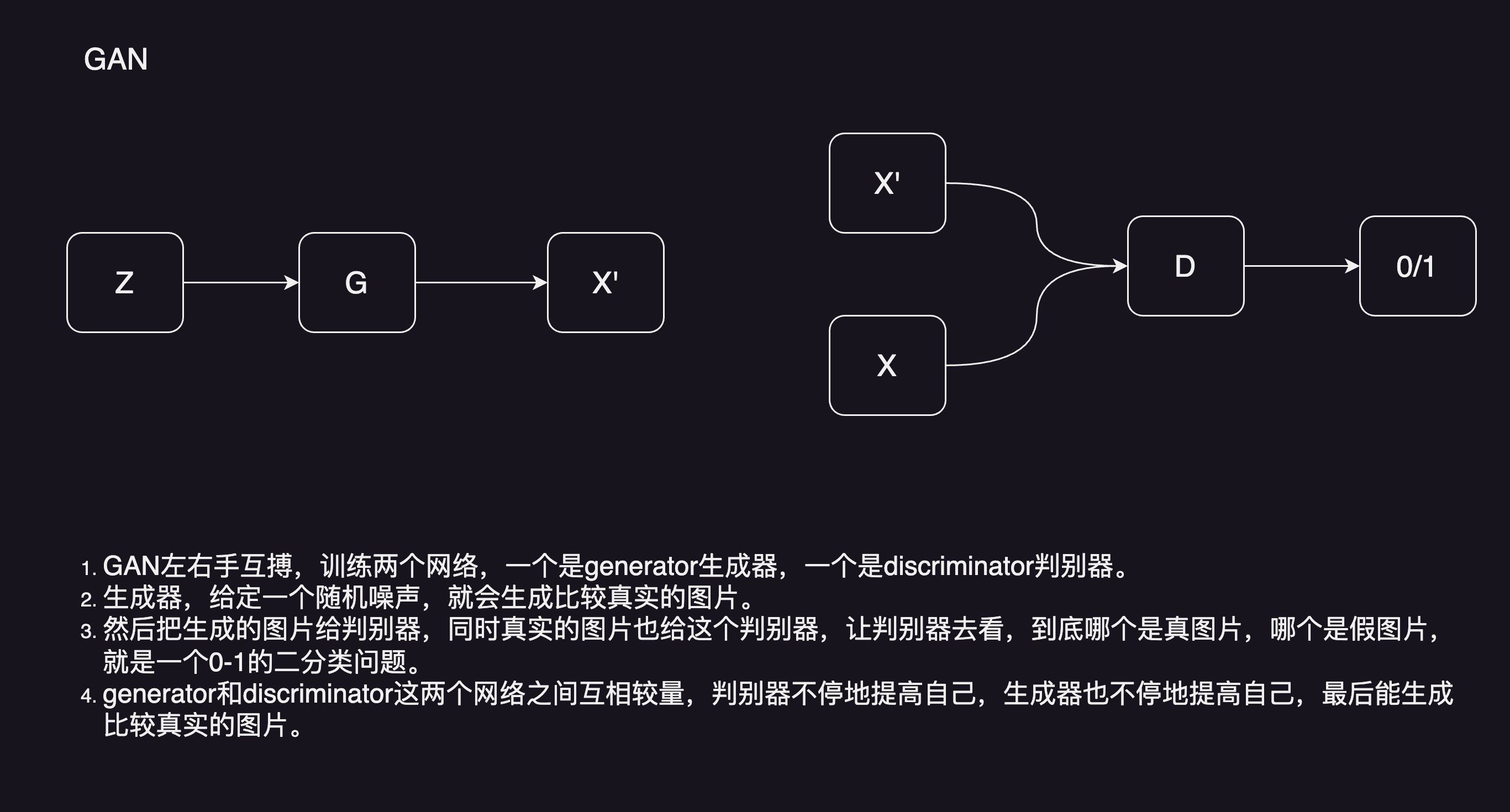
GAN模型左右手互搏,训练两个网络,一个是generator生成器,一个是discriminator判别器。生成器,给定一个随机噪声,生成比较真实的图片。然后把生成的图片给判别器,同时真实的图片也给判别器,让判别器去看,到底哪个是真图片,哪个是假图片,就是一个0-1的二分类问题。generator和discriminator这两个网络之间互相较量,判别器不停地提高自己,生成器也不停地提高自己,最后能生成比较真实的图片。
事实上,因为GAN的目标函数呢,就是用来以假乱真的,所以截止到目前为止,GAN生成的图片,保真度是非常高的。就真的是人眼,也不好区分它生成的图片是真是假。所以才有了DeepFakes的火爆。不光是真实,而且经过这么多年对GAN的模型的改造,GAN现在也比较好用,需要的数据也不是那么多,能在各个场景底下使用,优点还是蛮多的。
但它有一个最致命的缺点,那就是训练不够稳定。最主要的原因,就是要同时去训练这两个网络。所以就有一个平衡的问题,经常训练的不好,模型就训练坍塌了。
而且因为GAN的主要优化目标是让图片尽可能的真实,它生成图片的多样性就不太好。它的多样性,主要就来自于刚开始的随机噪声。简单点说,就是创造性还不太好,最后不是一个概率模型,生成都是隐式的,它是通过一个网络去完成的,你也不知道它做了什么,你也不知道它遵循了什么分布。所以GAN在数学上就不如后续的VAE或者这些扩散模型优美。
AE
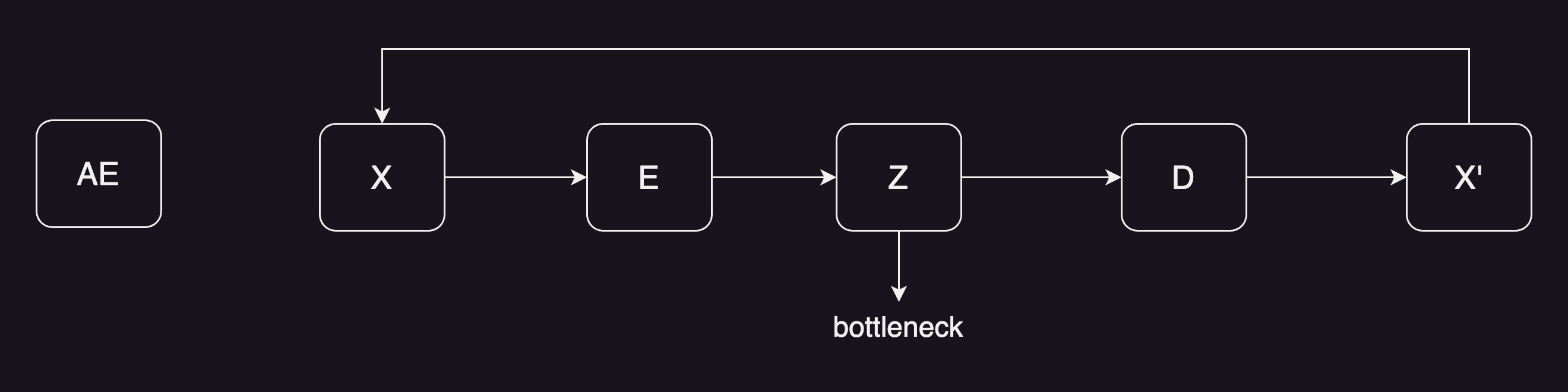
AE auto-encoder, 大概意思是给定一个输入x,过一下编码器,就能得到一个特征,特征的维度一般都会小很多,叫bottleneck。再从bottleneck开始,过一下解码器,最后得到一个图像。训练的时候目标函数是希望图像能尽可能的重建之前的x,因为是自己重建自己,所以叫auto-encoder。
DAE
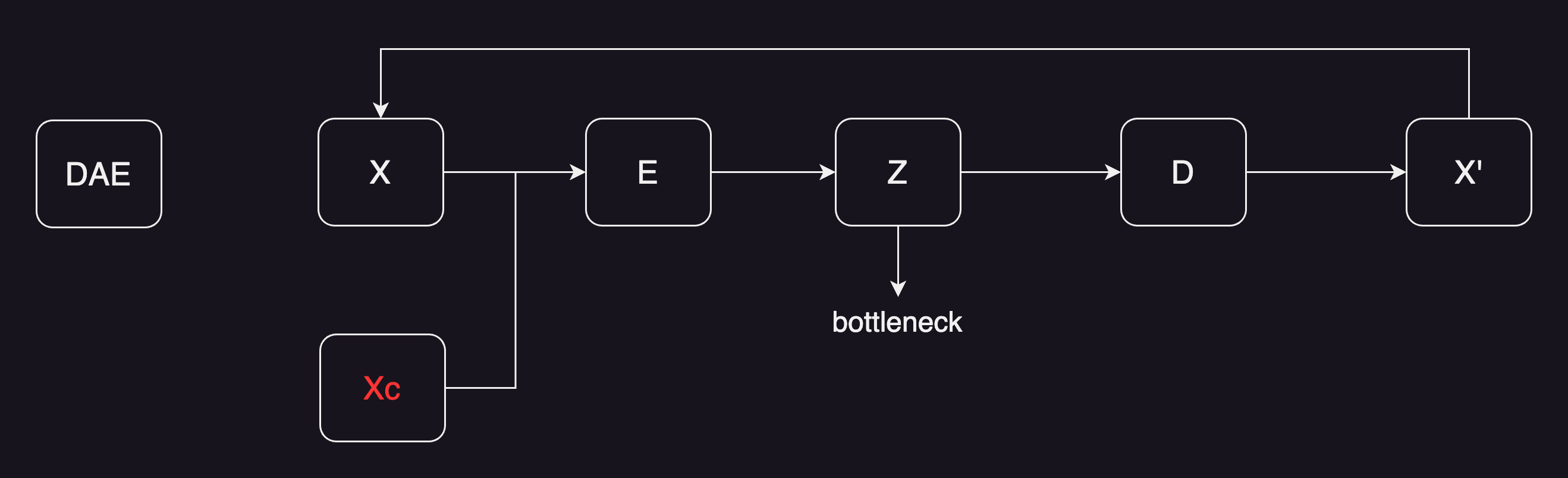
自编码器AE出来之后,紧接着就出来了denoising auto-encoder(DAE),其实就是先把原图,进行了一定程度的打乱。比如说变成了一个xc就是 corrupted x,然后把经过扰乱过后的输入,传给编码器,后续都是一样的。还是得到了一个bottleneck的特征,再通过解码器,最后得到一个输出。还是希望输出能够重建原始的x,而不是去重建经过扰动之后的x。
这个改进证明非常的有用,尤其是对视觉来说就更有用,会让训练出来的模型非常的稳健,也不容易过拟合。其实部分原因是图像像素冗余性太高了,所以即使把原来的图片做一些污染,其实模型还是能抓住它的本质,然后去把它重建出来的。这其实也就有点接近恺明 MAE(masked auto-encoder) 掩码自编码器,在训练的时候,之所以能够mask掉75%这么多图像区域,还能把图像很好的重建出来,也就说明了图像冗余性确实是高。这也从侧面证明了这种denoising auto-encoder,或者masked auto-encoder的有效性。
但其实不论是AE还是DAE还是MAE,它们主要的目的,都是为了去学中间bottleneck特征的,然后把特征,拿去做一些分类,检测分割这些任务,它并不是用来做生成的。原因就是学到的不是一个概率分布,没法对它进行采样。也就说这里z,并不像GAN里面那样是一个随机噪声,是一个专门用来重建的一个特征。但是这种encoder-decoder的形式,确实是一种很好的结构。那我们怎么能使用这种结构,去做这种图像生成呢❓
VAE
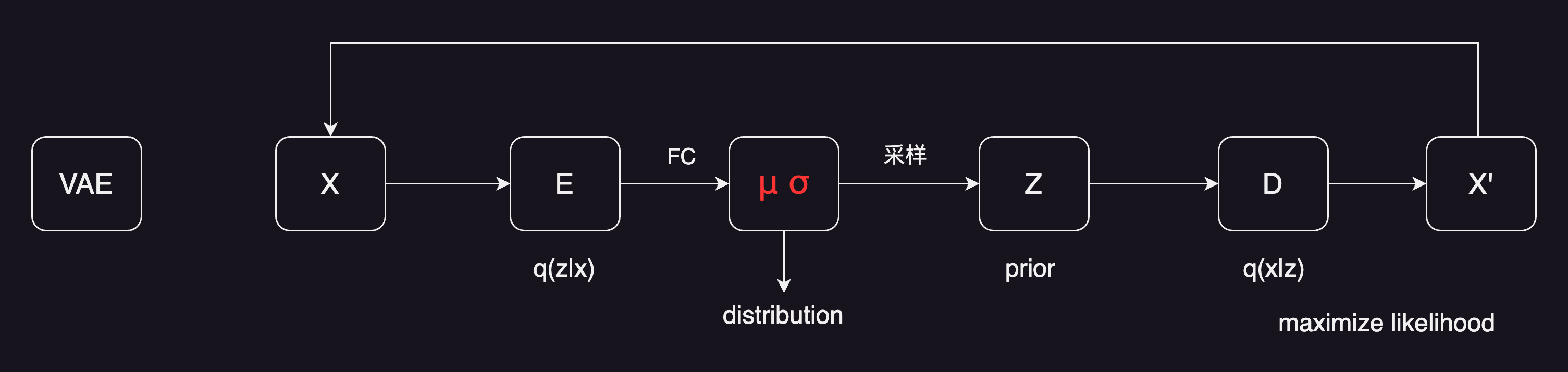
那我们怎么能使用这种结构,去做这种图像生成呢❓这就有了VAE (Variational Auto-encoder) 。VAE跟AE是非常不一样的,虽然它的整体框架看起来,还是一个输入,进了一个编码器,然后得到了一些东西,最后出解码器,得到一个输出。它的目标函数还是让输出尽可能的去重建原来的x。看起来好像一样,但其实有一个非常重要的区别。就是它的中间不再是学习,一个固定的bottleneck的特征了,而是去学习了一个分布。
在这里作者假设是一个高斯分布,用均值和方差来描述。具体来说,就是当我们得到从编码器出来的特征之后,在后面加一些FC层,去预测均值和方差,得到对应的均值和方差,就用公式去采样一个z出来。那这样VAE就可以用来做生成了。
因为在你训练好模型之后,完全可以把前面编码器直接扔掉,这里z可以从高斯随机噪声里去抽样出来一个样本,给解码器就能生成一张照片了。 然后因为VAE这里预测的是一个分布,从贝叶斯概率的角度来看,前面的这一过程,就是给定x得到z的过程,就是一个后验概率,学出来的distribution就是一个先验分布。至于后面这块就是给定了z然后去预测一张图片x的时候,其实就是maximize likelihood。从数学上看就优美很多。
而且VAE也有一些很不错的性质,比如说,因为它学的是一个概率分布,是从分布里去抽样,所以生成的图像多样性就比GAN要好得多。这也就是为什么大家接下来,做了很多基于VAE的后续工作,包括VQ-VAE还有VQ-VAE-2,以及再后来的DALL·E第1版模型,其实也是在VQ-VAE的基础上做的。
VQVAE
既然说到了VQ-VAE,那接下来我们就来讲一下。VQ-VAE这里的含义就是vector quantised,把VAE做量化,为什么要这么做,其实原因很简单,即使现实生活中,所有的信号包括声音,图像可能都是连续的,或者说大部分任务,可能都是一个回归任务,但事实真的当把它表示出来,真的去解决这些问题的时候,都把它离散化了,图像也是变成像素了,语音也都抽样过了。大部分工作的比较好的模型,也都是分类模型,又都从回归任务变成分类任务。
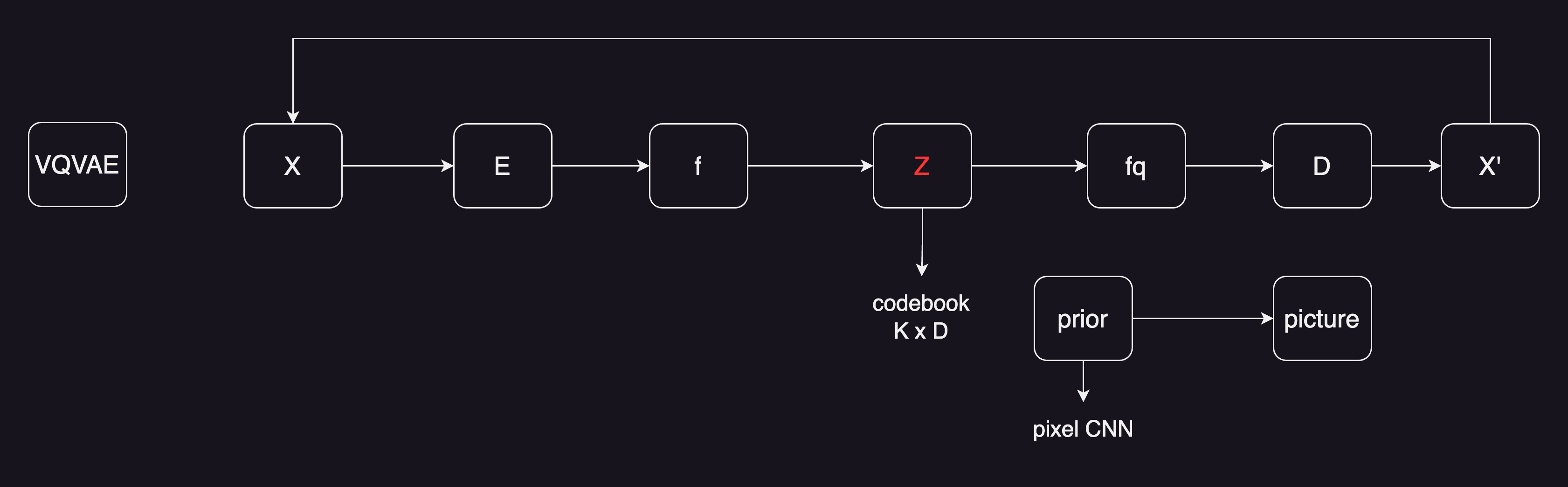
所以这里也一样,如果用之前VAE的方式,就不好把模型做大,图像的尺寸做大,而且这里分布也不是很好学。取而代之的,是不去做分布的推测,用一个codebook去代替。codebook的大小一般是K乘以D,K一般是8192,D一般是512或者768,就有8192个长度为D的个向量。在codebook里有8192个聚类中心。
这时候如果有一个图片,经过编码器得到了一个特征图,特征图是有长宽的,hw这种长宽的特征图。然后把特征图里的向量,去跟codebook里的向量去做对比,然后看看它跟哪个聚类中心最接近,就把最接近的聚类中心编码存到z矩阵里。所以这里可能就是一些编号,比如说1或者100之类的。
一旦做完聚类的分配,那我们就不用之前的特征f了。取而代之的是,用index对应的特征,如果编号为10,就把编号为10的向量拿出来,生成一个新的特征图叫做fq,就是quantised feature。经过量化后的特征,就非常的可控了。因为它永远都是从codebook里来的,不是随机的,所以优化起来就相对容易。有了特征图,跟之前的auto-encoder,或者VAE就差不多了。通过一个解码器,然后就去重构一张图片。目标函数还是让x’尽量跟x去保持一致,这样就完成了整个VQ-VAE的训练。
VQ-VAE学习的是一个固定的codebook,这意味着,它又没办法像VAE那样去做随机采样,然后生成对应的图片。准确说它不像是一个VAE,更像是一个AE,学的codebook和特征,是拿去做high level任务的,也就做分类、检测的。
如果想要做生成怎么办,对于VQ-VAE来说,需要单独再训练一个prior网络,在VQ-VAE论文里,作者又训练了一个pixel CNN,当做prior网络。利用已经训练好的codebook去做图像的生成。在VQ-VAE之后又有了VQ-VAE-2,是一个简单的改进,把模型变成层级式的了,不仅做局部的建模,而且做全局的建模,还加上了attention,对模型的表达能力变强了,同时还根据codebook,又去学了一个prior,所以生成的效果也非常的好。
CLIP
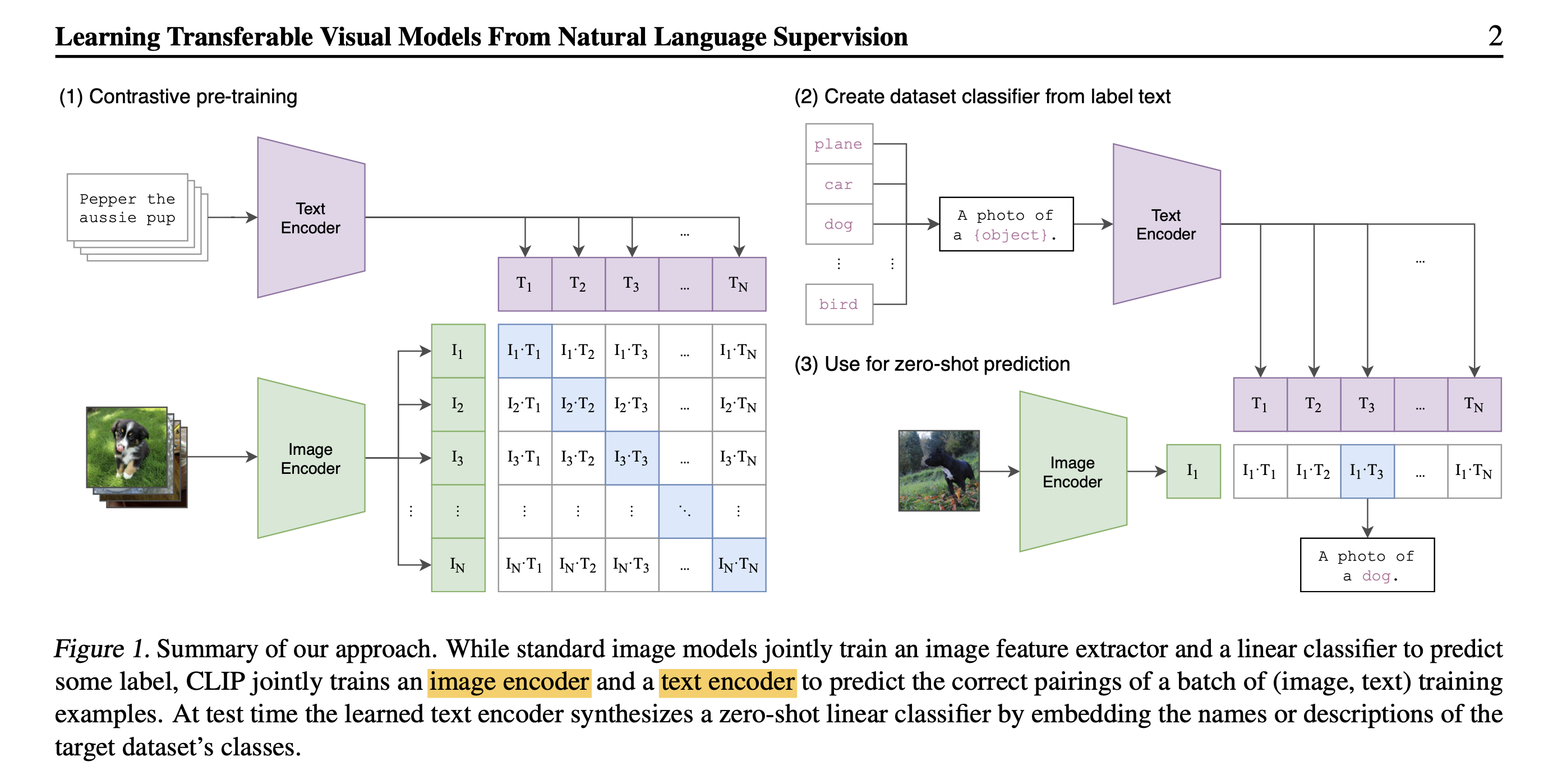
CLIP 论文提出了一种新的文本-图像对比学习模型,该模型可以学习文本和图像之间的对应关系。CLIP 模型使用 contrastive learning 的方法,通过最大化文本和图像特征之间的相似度,来学习文本和图像之间的对应关系。
模型结构
CLIP 模型由以下几个部分组成:
- 文本编码器
- 文本编码器负责将文本转换为一个向量表示。CLIP 模型使用 Transformer 作为文本编码器。Transformer 可以学习文本的全局和局部依赖关系。
- 图像编码器
- 图像编码器负责将图像转换为一个向量表示。CLIP 模型使用 ResNet 作为图像编码器。ResNet 可以学习图像的局部特征。
- 对比学习模块
- 对比学习模块负责计算文本和图像特征之间的相似度。CLIP 模型使用 cosine similarity 作为对比学习模块。
模型原理
CLIP 模型使用 contrastive learning 的方法来学习文本和图像之间的对应关系。Contrastive learning 的目标是最大化相似文本-图像对之间的相似度,同时最小化不同文本-图像对之间的相似度。
模型训练
CLIP 模型的训练过程如下:
- 从一个文本-图像对开始。
- 使用文本编码器将文本转换为一个向量表示。
- 使用图像编码器将图像转换为一个向量表示。
- 使用对比学习模块计算文本和图像特征之间的相似度。
- 计算损失函数值。
- 使用反向传播更新模型参数。
模型推理
CLIP 模型的推理过程如下:
- 将文本转换为一个向量表示。
- 将图像转换为一个向量表示。
- 使用对比学习模块计算文本和图像特征之间的相似度。
- 根据相似度判断文本和图像是否匹配。
DALL·E
VQ-VAE先训练一个codebook,然后又训练一个pixel CNN,去做生成。pixel CNN其实是一个auto regressive自回归的模型。
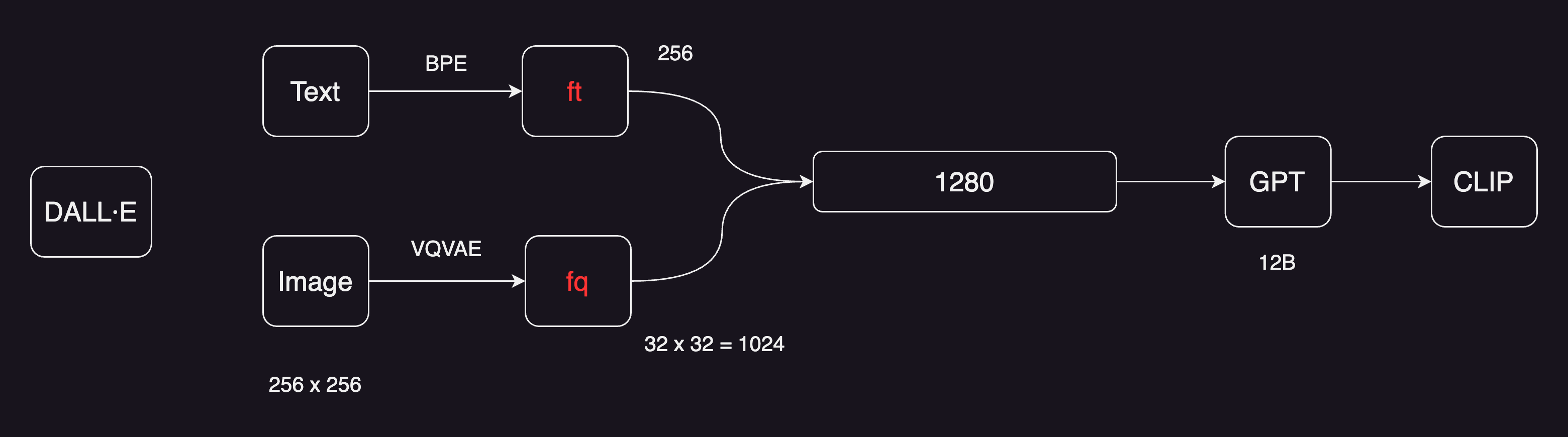
那还有什么模型是自回归呢,OpenAI的看家本领GPT系列。DALL·E从模型上看是非常简洁的,图像文本对的文本先通过BPE编码,得到特征有256维;图像是256*256,然后经过一个VQ-VAE,类似上面这种训练好的一个codebook,在DALL·E里是直接拿过来用。所以DALL·E也是一个两阶段的图像生成器。
把原来的图像变成图像特征之后,维度就下降了很多,从256256变成了3232,一共有1024个token。文本特征和图像特征直接连接起来,变成了一个1280个token的序列。接下来就是把序列扔给一个GPT,遮住的地方遮住,让GPT模型去预测一个就好了。
推理方面,只需要提供一个文本,把文本变成文本特征,直接用自回归的方式,把图像生成出来。当然了DALL·E的论文还有很多的细节,比如说会生成很多的图片,到底选哪一张,会用CLIP模型,做一个排位,把生成出来的图片跟文本最贴切的那个图片挑出来,当做最后的生成图像。
Diffusion Model
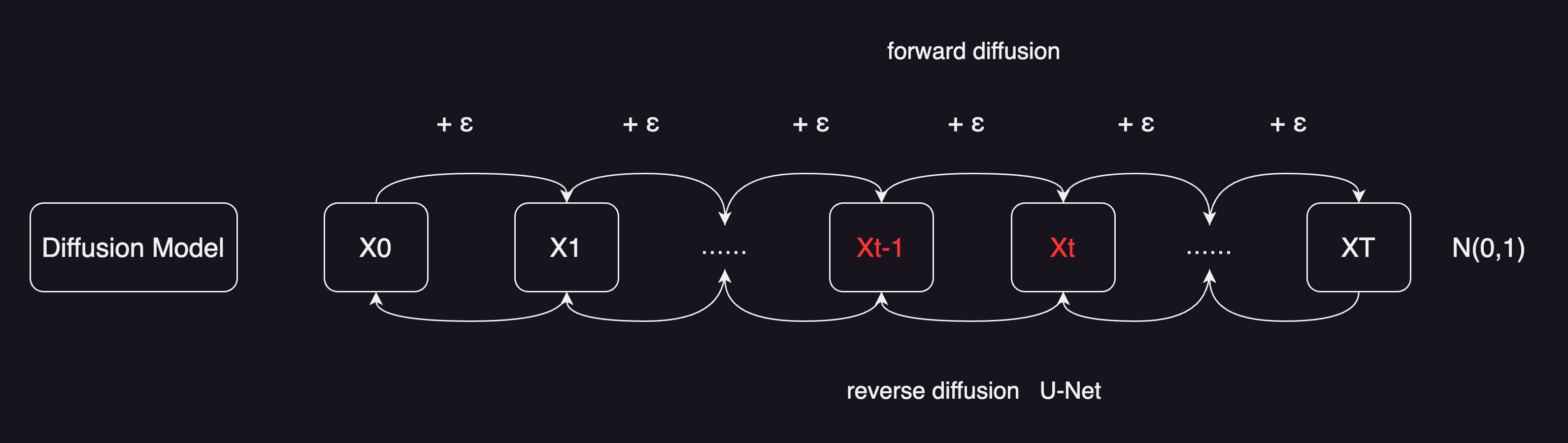
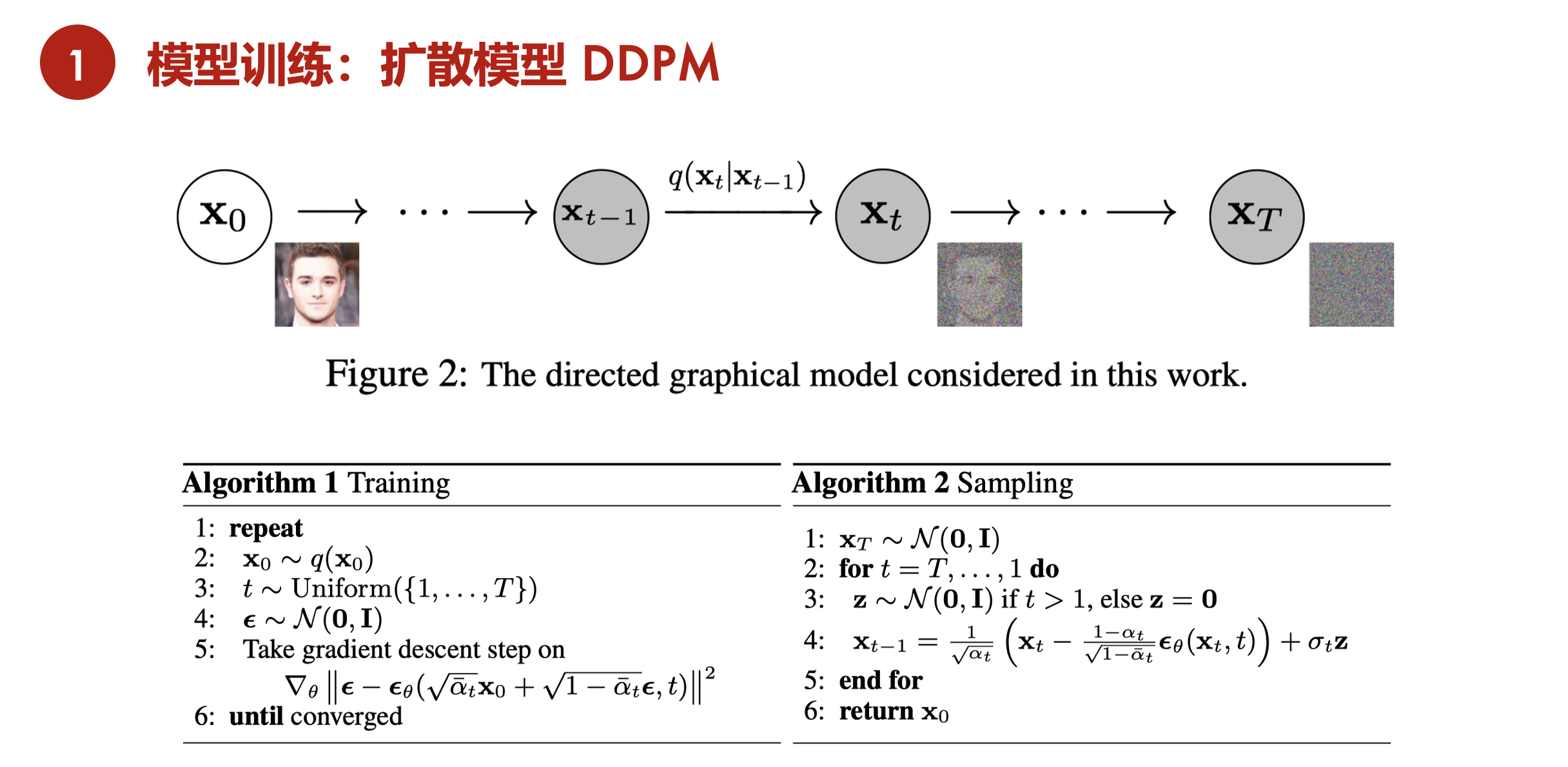
diffusion model叫扩散模型,假设有一个图片X0,然后往图片里去加噪声,比如说每一步,都往里加一个很小的一个正态分布的噪声,得到了X1,那X1其实是在X0的基础上,比如说多点了几个杂的点,再继续给它加个噪声,一直加到最后,比如一共加了t次,如果t特别特别的大,最终它就会变成一个真正的噪声,就变成一个正态分布,或者更专业一点,一个各向同性的正态分布,整个过程就叫做 forward diffusion,就是前向扩散过程。
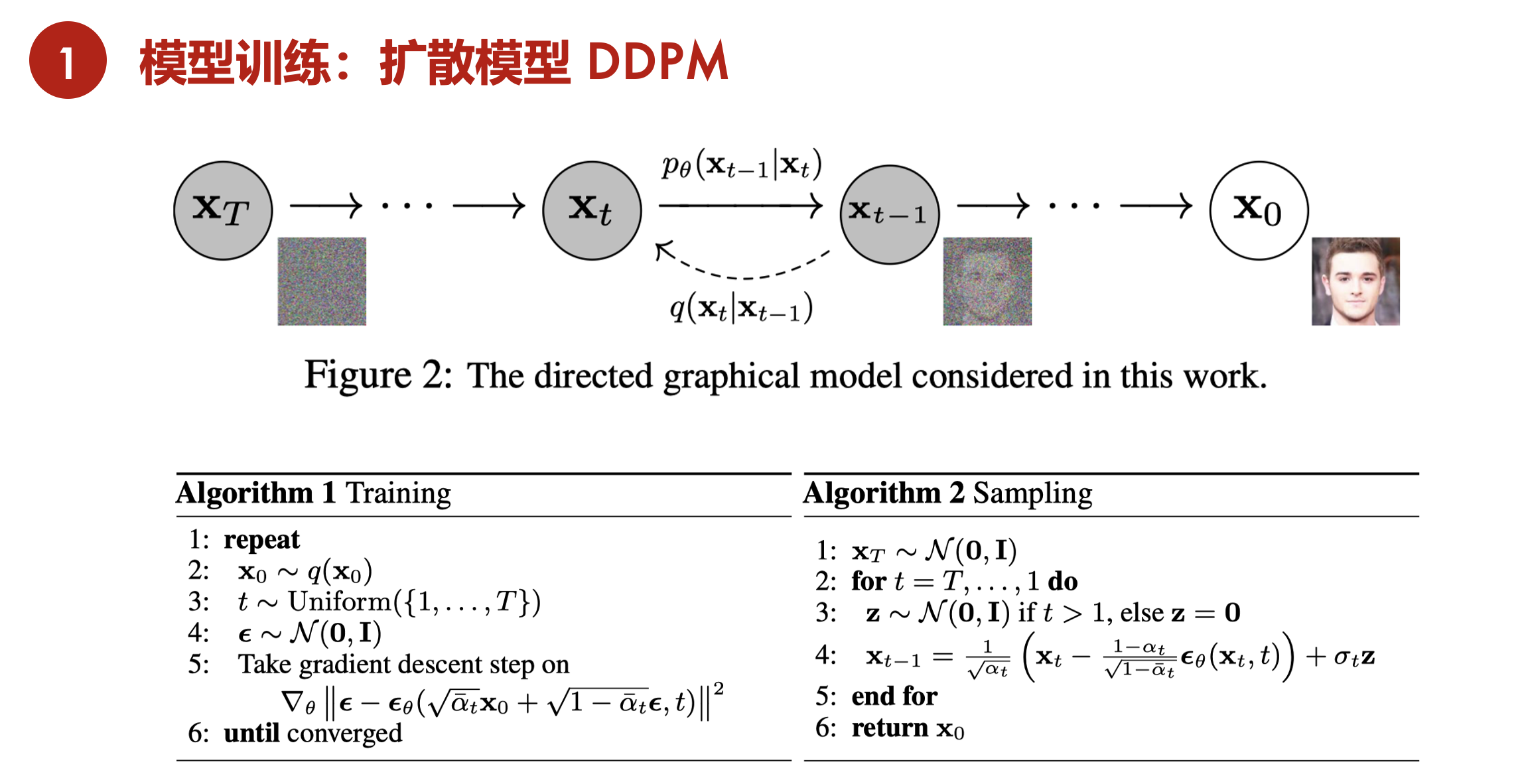
如果反过来想,现在输入是一个随机噪声,也就是GAN里面的那个z,如果能找到一种方式,或者训练一个网络,能够慢慢的把噪声,一点一点这样再恢复回来,恢复到最初的图片,就可以做图像生成了。事实上,扩散模型就是这么简单,通过反向过程,去做图像生成的。
随机抽样一个噪声,比如Xt或者之前的任意一步,训练一个模型,把它从Xt变到Xt-1,再用同样的模型去把Xt-1变成Xt-2,然后一步一步这样倒退回来。这里使用的模型都是共享参数的,就只有一个模型,只不过你要抽样生成很多次,所以这可能也是扩散模型一个非常大的一个不足。就是说,训练上跟别的模型比起来,也是比较贵的;在推理的时候,就更别说了,是最慢的。因为像GAN,只要模型训练好了,给它一个噪声,一下就给出来一张图片,是非常的快,做一次模型forward就可以了。但对于扩散模型来说,尤其是对于最原始的扩散模型来说,一般t是选择1000步,随机选择了一个噪声,要做1000次forward,一点一点把图像恢复出来,那开销是远远大于其他生成模型的。
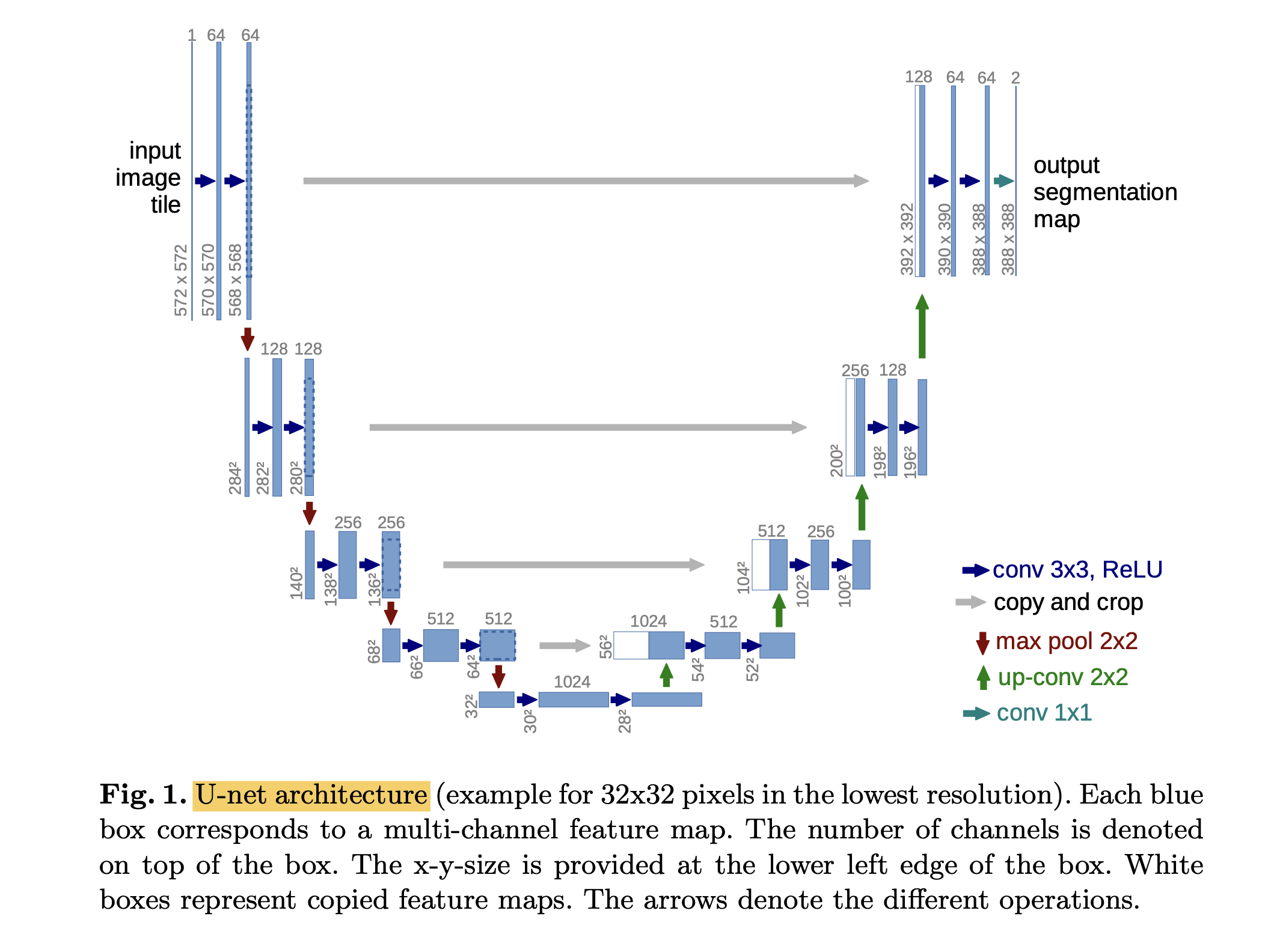
在reverse diffusion过程中,模型是U-Net,U-Net就是一个CNN,先有一个编码器,一点一点把图像压小;然后再用一个解码器,一点一点把图像再恢复回来,前后的这两个图像尺寸大小是一样的。为了让恢复做得更好,U-Net里还有一些这种skip connection,直接把信息从前面推过来,这样能恢复一些细节。对网络结构还有一些改进,比如说给U-Net里也加上这种attention操作,会让图像生成变得更好。这里面模型也不一定要用U-Net,也可以用其他的。
U-Net
LDM
LDM, Latent Diffusion Models
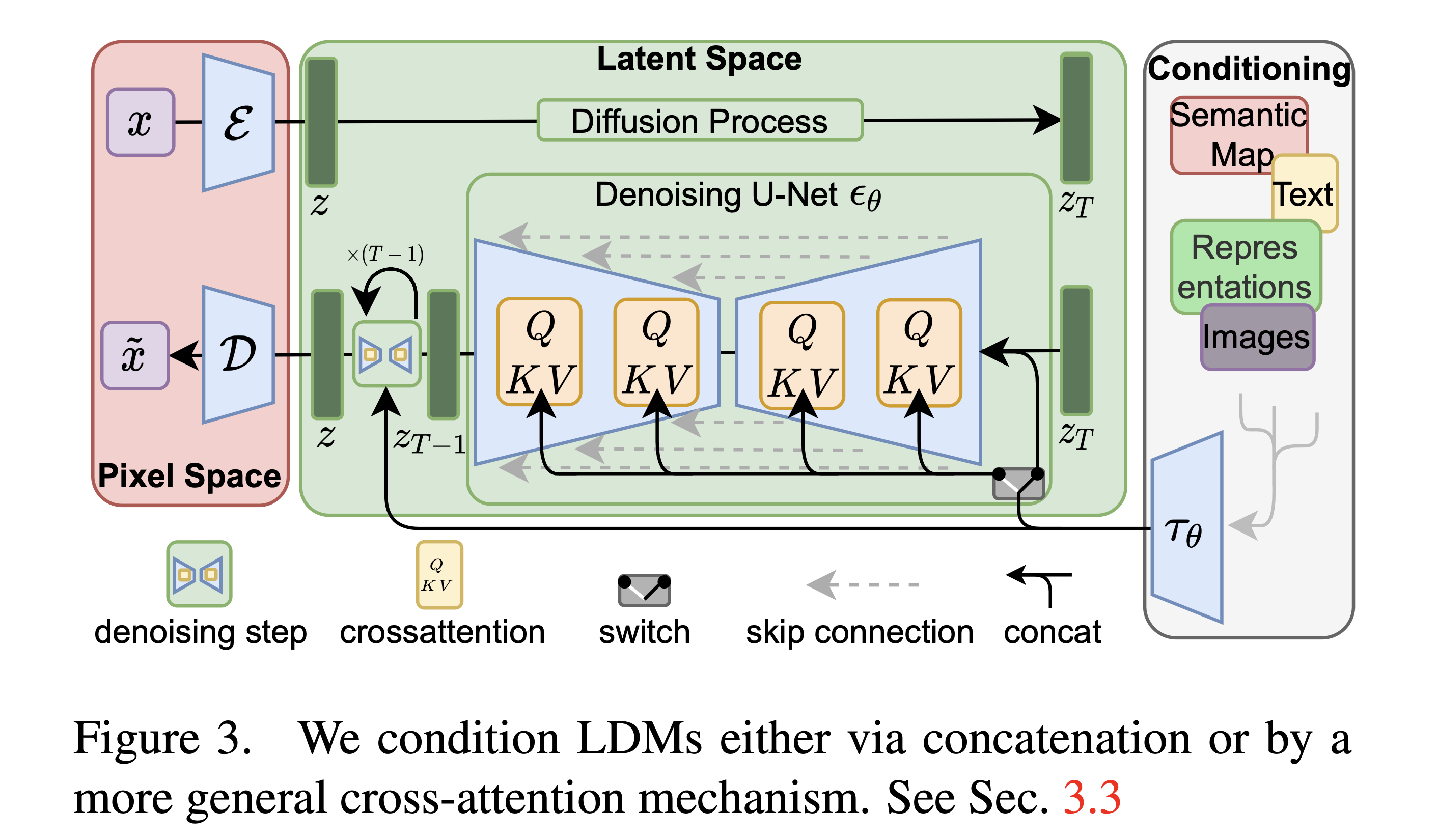
LDM (Latent Diffusion Models) 是一种生成模型,它在压缩的潜在空间中进行操作,以提高计算效率。具体来说,LDM 由一个自编码器和一个扩散模型组成。自编码器负责将图像编码到低维潜在空间,并从该空间解码以重建图像。扩散模型则在这个潜在空间中学习生成图像的分布。
训练过程通常包括两个阶段:首先训练自编码器以获得高质量的图像重建,然后在潜在空间中训练扩散模型以生成新的图像样本。在推理过程中,可以通过从扩散模型中采样并使用自编码器的解码器将样本映射回图像空间来生成新的图像。
这项研究对使用扩散模型进行高分辨率图像合成领域做出了重大贡献。它提出了一种方法,与直接生成高分辨率图像相比,显著降低了计算成本,同时保持了质量。换句话说,它展示了通过编码并将扩散过程引入到潜在空间(持有图像压缩表示的低维空间)中表示的数据,可以用更少的计算资源实现。
Sora将这项技术应用于视频数据,将视频的时空数据压缩到低维的潜在空间中,然后进行分解成时空补丁的过程。这种高效的数据处理和生成能力在潜在空间中发挥着至关重要的作用,使Sora能够更快地生成更高质量的视觉内容。
DDPM
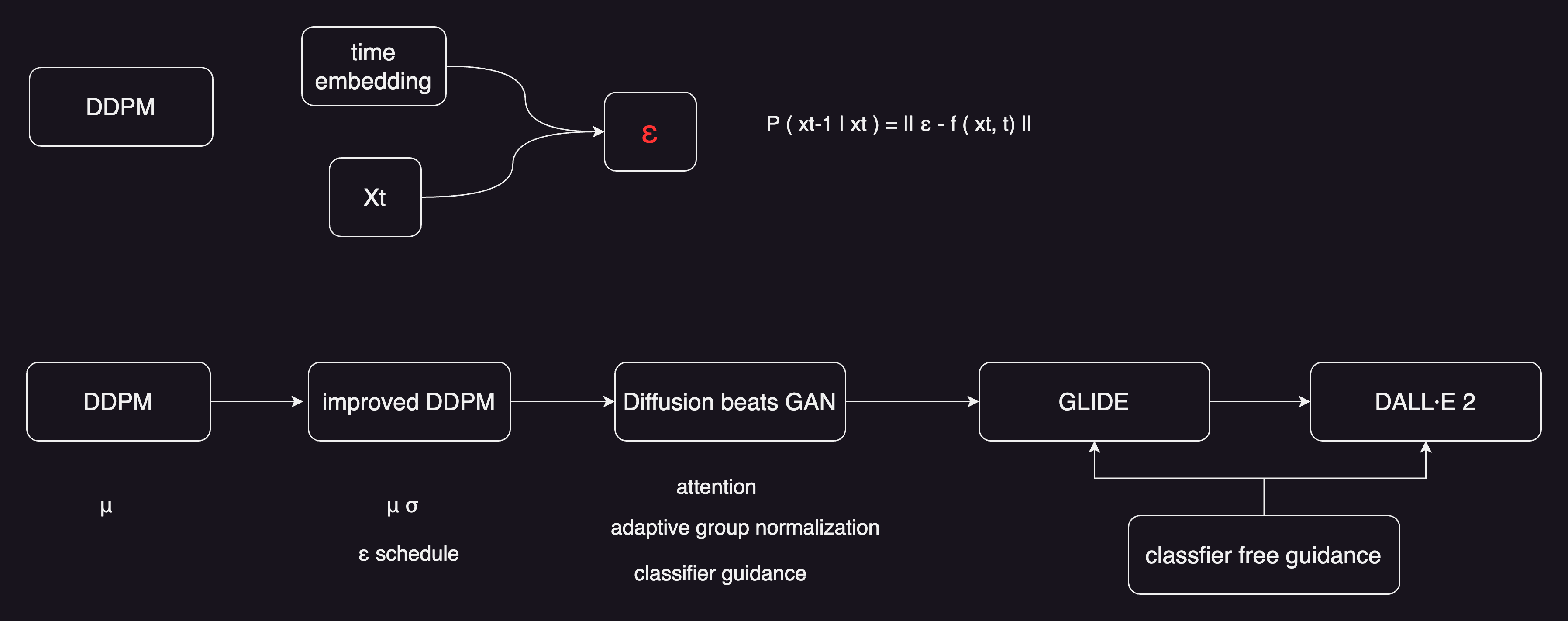
Denoising Diffusion Probabilistic Model 就是DDPM,对原始的扩散模型,做了一些改进。把优化过程变得更简单了,最重要的两个贡献:
一个是之前都觉得是要用Xt去预测Xt-1,这种图像到图像的转化,DDPM就觉得可能不好优化。那么不去优化图像的转换,而是预测从Xt-1到Xt,噪声是怎么加的。这有点ResNet的意思,本来是直接用x去预测y,但直接预测y太难了,把问题理解成y等于x加上一个residual,只去predict残差residual就可以了。这里面也是一个意思,不去预测Xt-1,而是去预测加了多少噪声,一下就把问题给简化了。DDPM论文里还有一些其他的改进,比如说加了time embedding,time embedding就是告诉模型,现在走到了反向扩散的第几步,输出是想要糙一点的,还是想要细致一点的。time embedding对整个图像的生成和采样过程都很有帮助。
第二个贡献是,预测一个正态分布只要学均值和方差就可以了。作者这里发现其实只要预测均值就可以了,方差都不用学,直接用一个常数就可以了。这样也是简化了模型的优化。
DDPM forward diffusion
DDPM reverse diffusion
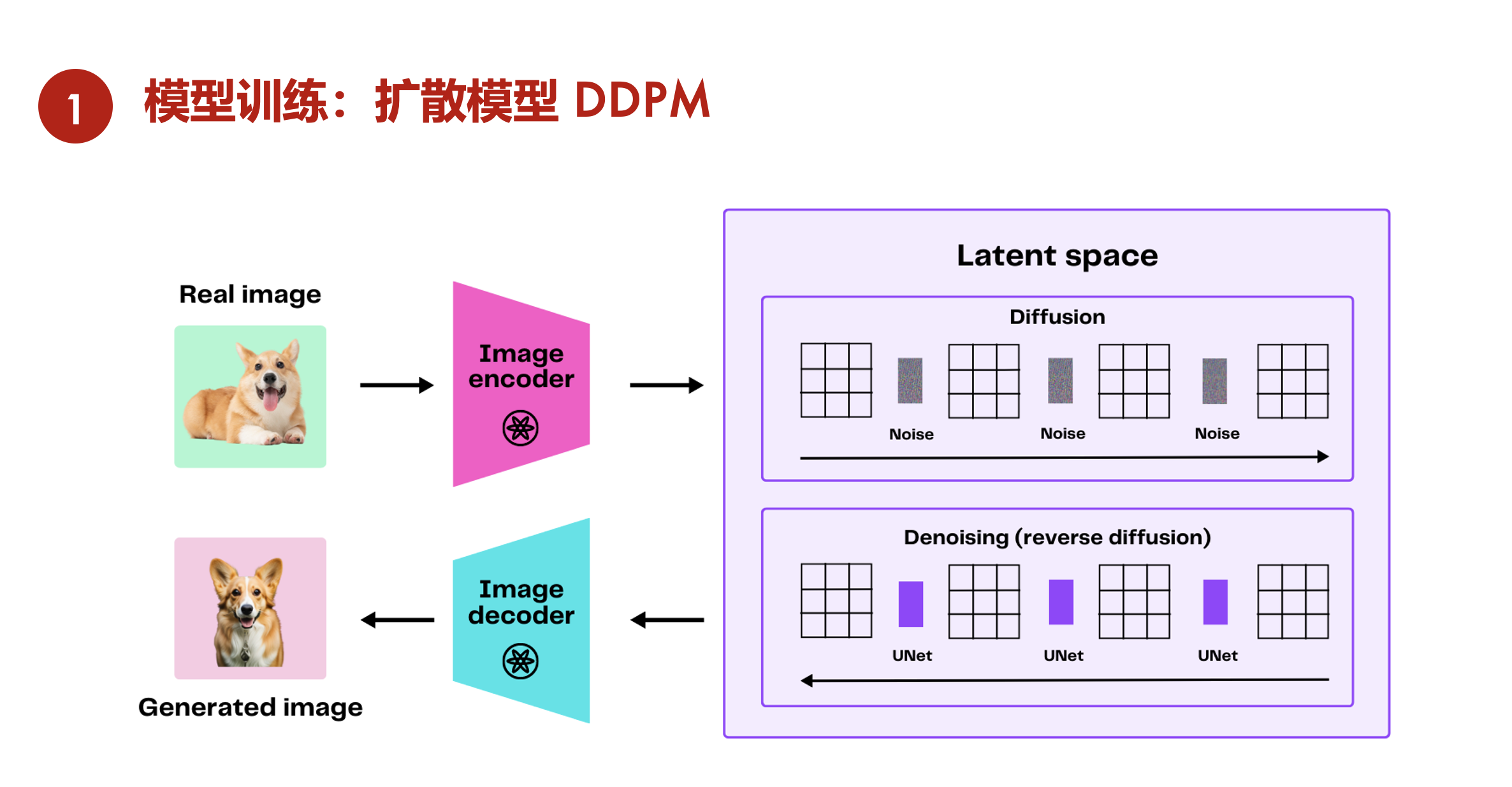
DDPM latent space
DDPM VS VAE
- 都是一个编码器-解码器的结构,只不过扩散模型中,编码器一步一步走到中间的z,是一个固定的过程。而对于VAE来说,编码器是learn的,中间的z是learn的。
- 扩散模型每一步的中间过程,跟刚开始的输入,都是同样维度大小的。对于一般的AE、VAE这种编码器解码器的结构来说,中间的bottleneck特征往往是要比输入小很多。
- 扩散模型有步数的概念,从随机噪声开始,要经过很多步才能生成一个图片,有time step、time embedding这些概念。在所有的time step里,U-Net模型结构都是共享参数的。而在VAE里不存在这一点。
扩散模型一旦做work了之后,大家的兴趣一下就上来了。因为在数学上特别的简洁美观,不论是正向还是逆向,都是高斯分布。
improved DDPM,大概就是在同年20年底放到arXiv上,做了几个改动
- DDPM里说正态分布的方差不用学,用一个常数就可以了。improved DDPM 把方差学了,后面的取样和生成效果都不错
- 优化噪声的schedule,从一个线性的schedule,变成了一个余弦的schedule
Diffusion model beats GAN,紧接着几个月之后,就出来了这一篇论文
- 把模型加大加宽,增加自注意力头的数量attention head
- 提出一个新的归一化的方式 adaptive group normalization。根据步数做这种自适应的归一化,发现效果也非常不错
- 使用 classifier guidance的方法,引导模型做采样和生成。不仅让生成的图片更加的逼真,而且也加速了反向采样的速度。论文中就做25次采样,就能从一个噪声,生成一个非常好的图片,加速了相当多。
Classifier Guided Diffusion
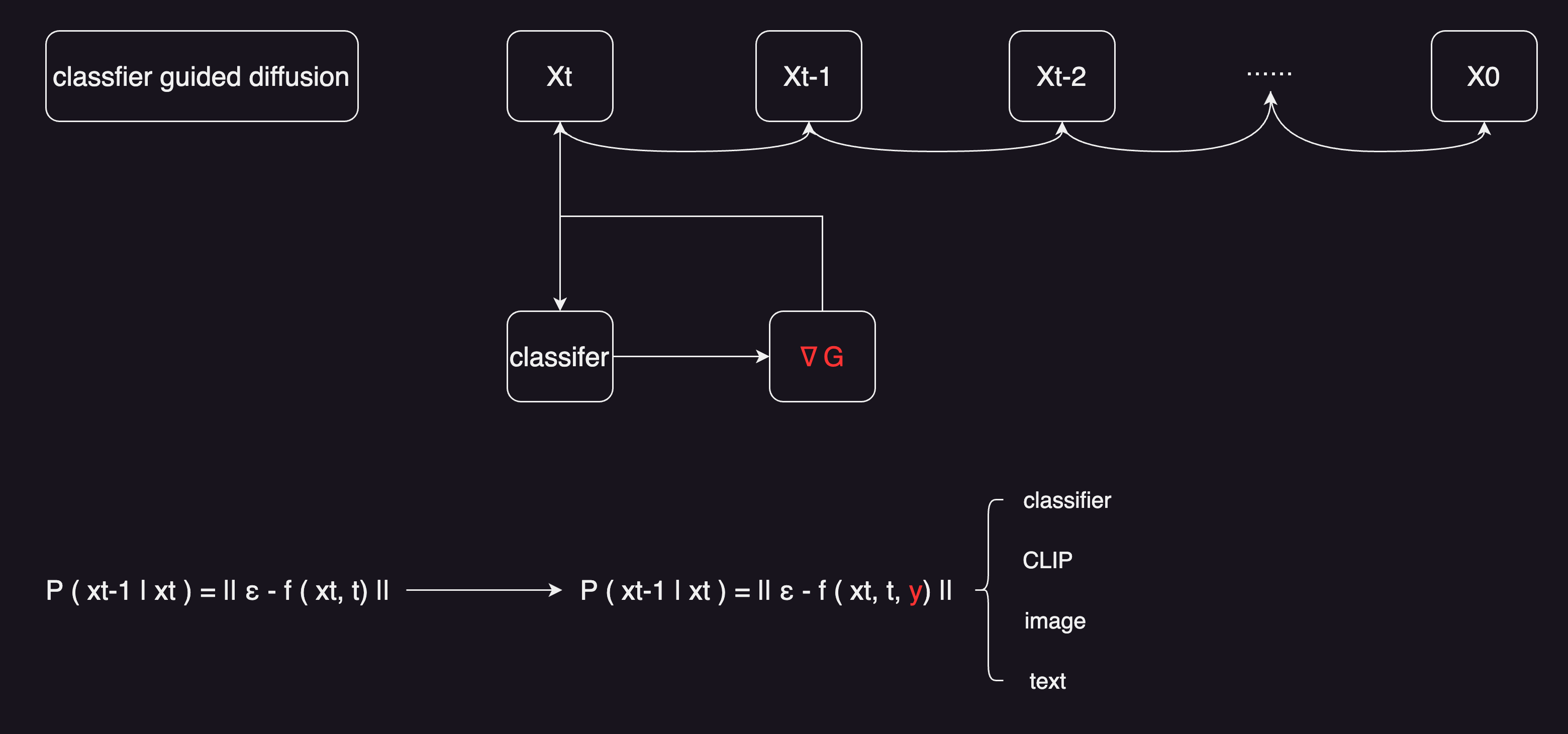
- 图片分类器的作用:当有一个图片Xt之后,直接扔给分类器,去看分类的对不对。能算一个交叉熵目标函数,对应的就会得到一些梯度,用梯度,去帮助模型进行采样和图像的生成。
- 那有什么好处呢,因为这里的梯度,大概暗含了当前图片到底有没有一个物体,或者说现在生成的物体真不真实,通过这种梯度的引导,告诉U-Net,现在生成的图片,要看起来更像某一类物体,不是说意思到了就行,物体的形状颜色,纹理各种细节,都尽量的要跟真实的物体去匹配上。
- 所以说,经过了classifier guided diffusion操作之后,生成的图片就逼真了很多。这些IS或者FID score上,大幅度的提升了。也就是在这篇 diffusion model beats GAN的论文里,扩散模型,第一次在这些分数上,超越了之前比较好的一个GAN模型。
除了比较原始的这种classifier guided diffusion之外,还能用什么当做指导信号呢
- classifier
- CLIP
- image
- text
Classifier-Free Guidance
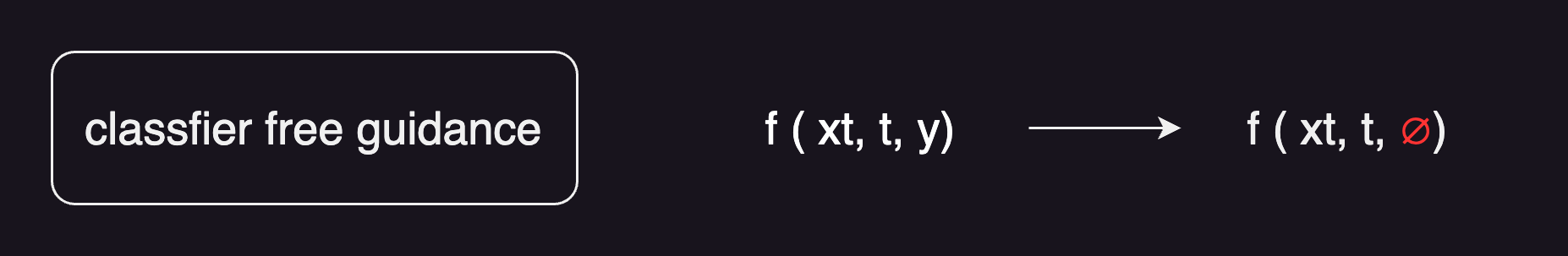
但这一系列的方法都有一个缺陷,真的都是又用了另外一个模型去做这种引导。要么用一个直接pre-train好的模型,要么还得去训练这么一个模型。不仅成本比较高,而且训练的过程也不可控。所以说就引出来了后续的一篇工作 classifier-free guidance。意思就是不想要这些classifier,还能不能找到一种指导信号,让模型的生成变得更好呢❓
在训练模型的时候,生成了两个输出。一个是在有条件的时候生成了一个输出,一个是在没有条件的时候,生成了一个输出。举个例子,比如说训练的时候,用的是图像文本对,想用文本去做guidance信号,y就是一个文本,在训练的时候,用文本y生成了一个图像,然后随机把文本条件去掉,用一个空集就是一个空的序列,再去生成另外一个输出。假设现在有一个空间,刚才生成的两个图片,分别是没有用y条件的,生成了一个X;用了y条件,生成了一个Xy。有一个方向,能从这种无条件最后得到的输出,成为有条件得到的输出,通过训练最后会知道它们两个之间大概的差距是多少。
最后去做这种反向扩散,去真正做图像生成的时候,当有了一个没有用条件生成的图像输出的时候,也能做出一个比较合理的推测,能从一个没有条件生成的X,变成一个有条件生成的X。这样就摆脱了分类器的限制,所以说叫classifier-free guidance。
这个方法,在模型训练的时候也是非常贵的。因为扩散模型本来训练就已经很贵了,结果使用这种classifier-free guidance的方法,在训练的时候还要生成两个输出,一个有条件的一个没条件的,所以又增加了很多训练的成本。但总之,classifier-free guidance一经提出,大家就觉得它真的是一个很好用的方法,不光是在GLIDE这篇论文里用到了,而且之后的DALL·E 2也用到了,还有Imagen呢也用到了。而且这几篇论文里都说这是一个非常重要的技巧。
DALL·E 2
论文:Hierarchical Text-Conditional Image Generation with CLIP Latents
链接:https://arxiv.org/abs/2204.06125
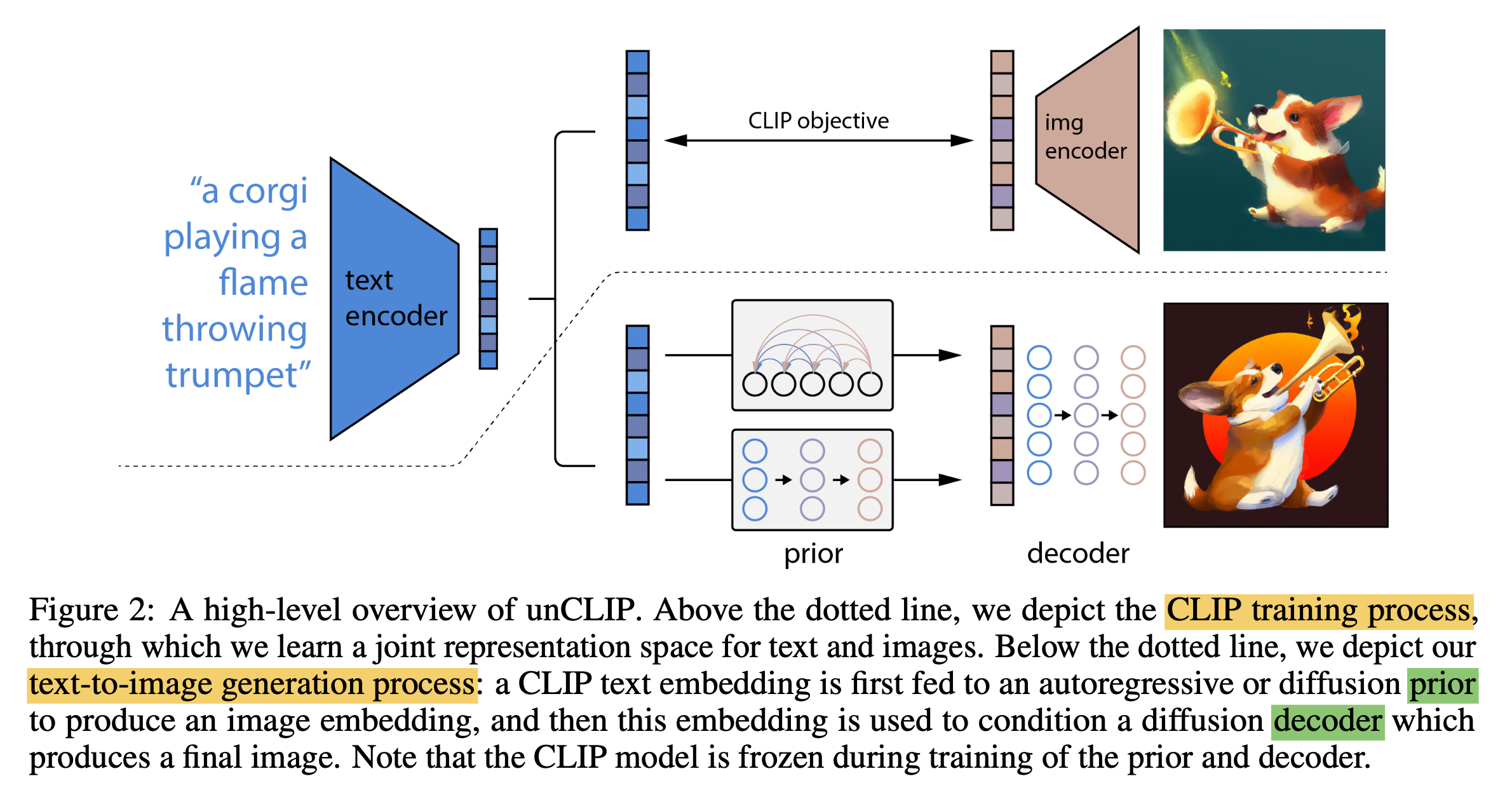
CLIP(Contrastive Language-Image Pre-Training)
- CLIP是一种用于文本-图像对编码的模型,由OpenAI之前开发。
- 它包含一个文本编码器(基于Transformer)和一个图像编码器(基于Vision Transformer)。
- 在DALLE 2中CLIP被用于编码输入的文本prompt,生成相应的文本嵌入向量表示。
- CLIP通过对比损失函数在大规模文本-图像数据集上进行预训练,学会将语义相近的文本和图像编码到相近的向量空间。
Prior(先验网络)
- Prior的作用是从一个随机噪声分布中,生成一个初始的潜在图像表示(latent image representation)。
- Prior由多个先验残差块(Prior Residual Blocks)组成,每个残差块包含卷积层和GroupNorm层。
- Prior会被训练成能从噪声中采样出有意义的初始图像表示,为后续的Decoder提供良好的起点。
Decoder(解码器网络)
- Decoder的结构类似于U-Net,是一种常用的生成式对抗网络架构。
- Decoder包括下采样(Downsampler)和上采样(Upsampler)部分,以及多个残差块。
- Decoder的输入是Prior生成的初始潜在图像表示,以及CLIP编码的文本嵌入向量。
- Decoder通过一系列的卷积、上采样等运算,将输入的潜在表示”解码”生成最终的图像输出。
- Decoder被训练以生成与输入文本描述相匹配的图像。
训练过程
- 使用大规模的文本-图像对数据集,预训练CLIP模型获得文本和图像编码能力。
- 在CLIP的基础上,使用扩散模型的框架联合训练Prior和Decoder网络。
- Prior被训练成能从噪声中采样有意义的初始图像表示。
- Decoder被训练成能将Prior的输出与CLIP编码的文本嵌入相结合,生成与文本描述相匹配的图像。
- 训练使用逆向扩散过程,最大化生成图像与真实图像的相似性。
- 整个训练过程计算量大、迭代次数多、算力需求高。
推理过程
- 输入文本prompt,由CLIP的文本编码器编码成嵌入向量。
- Prior从噪声分布中采样出一个初始的潜在图像表示。
- Decoder将Prior的输出与CLIP文本嵌入相结合,解码生成最终图像。
- 生成的图像与输入的文本prompt是语义相关的。
总的来说,DALLE 2 利用了CLIP的文本-图像编码能力,并在扩散模型框架下训练Prior和Decoder网络,实现了根据任意文本描述生成高质量图像的能力。其中各个模块结合运作完成整个任务。
Vit
论文:An Image is Worth 16x16 Words- Transformers for Image Recognition at Scale
链接:https://arxiv.org/abs/2010.11929
《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》(简称ViT,Vision Transformer)是一篇在图像识别领域开创性的论文,它首次将Transformer结构成功应用于图像识别任务中。这篇论文由Google Research的Alexey Dosovitskiy等人于2020年撰写。下面我将对ViT的主要内容进行详细解读。
- ViT 尝试将标准 Transformer 结构直接应用于图像;
- 图像被划分为多个 patch 后,将二维 patch 转换为一维向量作为 Transformer 的输入
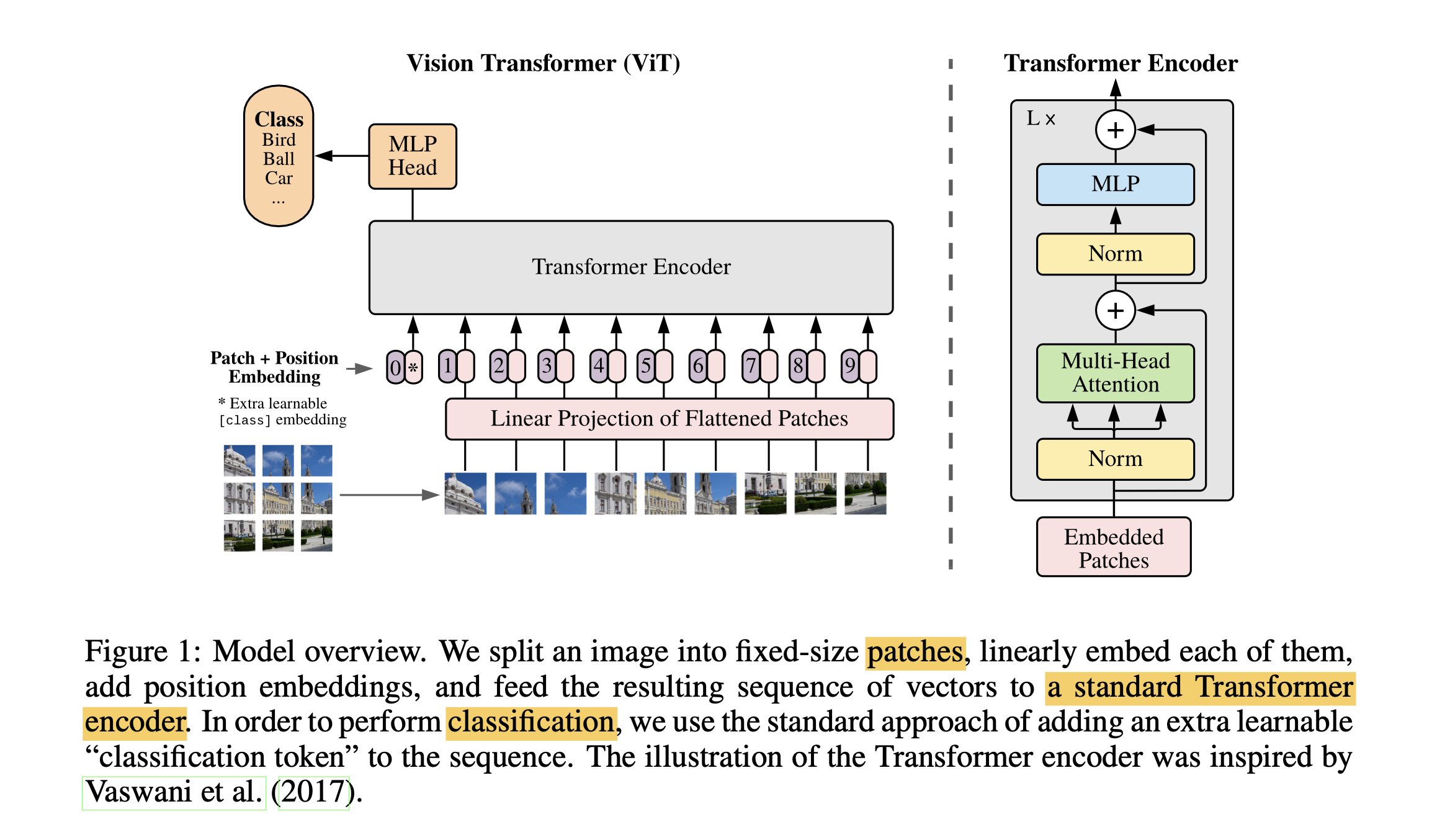
传统的图像识别方法主要依赖于卷积神经网络(CNN),而ViT论文提出了一种新的方法,即直接将Transformer应用于图像上,不依赖于任何卷积层。作者发现,当模型规模和数据量足够大时,ViT在图像识别任务上的表现可以超越当时的最先进模型。
ViT的核心思想就是将图像分割成一系列的patches(小块区域),把这些patches当做”视觉令牌(tokens)”输入到Transformer模型中。Transformer模型会利用注意力机制捕捉patches之间的关联关系,最终对整个图像做出分类或其它任务上的预测。
模型架构
ViT模型的基本思想是将图像划分为一系列的小块(patches),然后将这些小块视为序列中的“单词”(words),最后使用标准的Transformer模型进行处理。具体步骤如下:
- 图像切分:将输入图像切分成大小为16x16的小块(patches),每个小块被拉平成一个向量。
- 线性嵌入:使用一个线性层将每个小块的向量映射到一个高维空间,得到与Transformer模型中词嵌入类似的图像嵌入。
- 位置编码:为了让模型能够理解图像中不同小块的位置信息,每个图像嵌入都会加上一个位置编码。
- Transformer编码器:将上述处理后的图像嵌入序列输入到标准的Transformer编码器中,进行特征提取和信息交互。
- Norm层(Norm Layer): 对编码器的输出做归一化处理。
- 分类头(Classification Head): 对归一化后的编码器输出,通过一个小的前馈网络进行分类或其它任务的预测。
ViT模型的训练过程
- 使用大规模标注图像数据集(如ImageNet)进行监督式预训练。
- 以图像和对应标签为输入输出样本对。
- 逐批次迭代优化模型参数,最小化分类损失函数。
- 采用特殊的数据增强技术(如随机裁剪、颜色抖动等)。
- 模型规模很大(如ViT-Huge有632M参数),需要TPU等强大算力进行训练。
- 推理阶段时,只需将待分类图像切分成patches,输入到训练完毕的ViT模型,模型即可输出预测的类别标签。
ViT的优势在于摆脱了CNN的局限性,用注意力机制建模了patch之间的长程依赖关系,进一步提升了图像分类准确率。缺点是计算量和内存消耗较大,需要大量数据和算力进行训练。
总结与展望 ViT证明了Transformer结构在图像识别任务上的有效性,为后续研究提供了新的方向。但是,ViT也存在一些局限性,比如对大量数据和计算资源的依赖,以及对小数据集的泛化能力有待提高。后续的研究可以探索更高效的训练方法、更好的泛化能力以及Transformer结构在其他计算机视觉任务中的应用。
ViViT
论文:A Video Vision Transformer
链接:https://arxiv.org/abs/2103.15691
视频视觉变换器(ViViT)
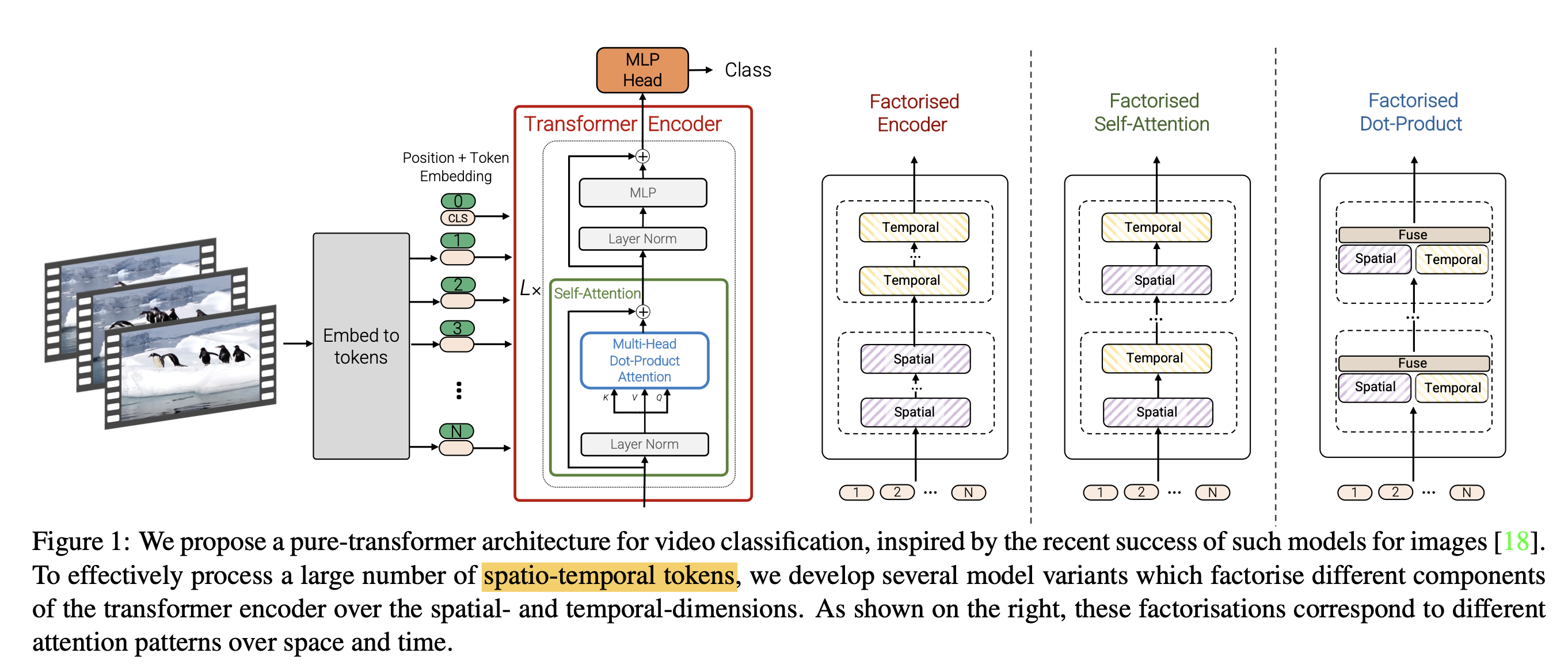
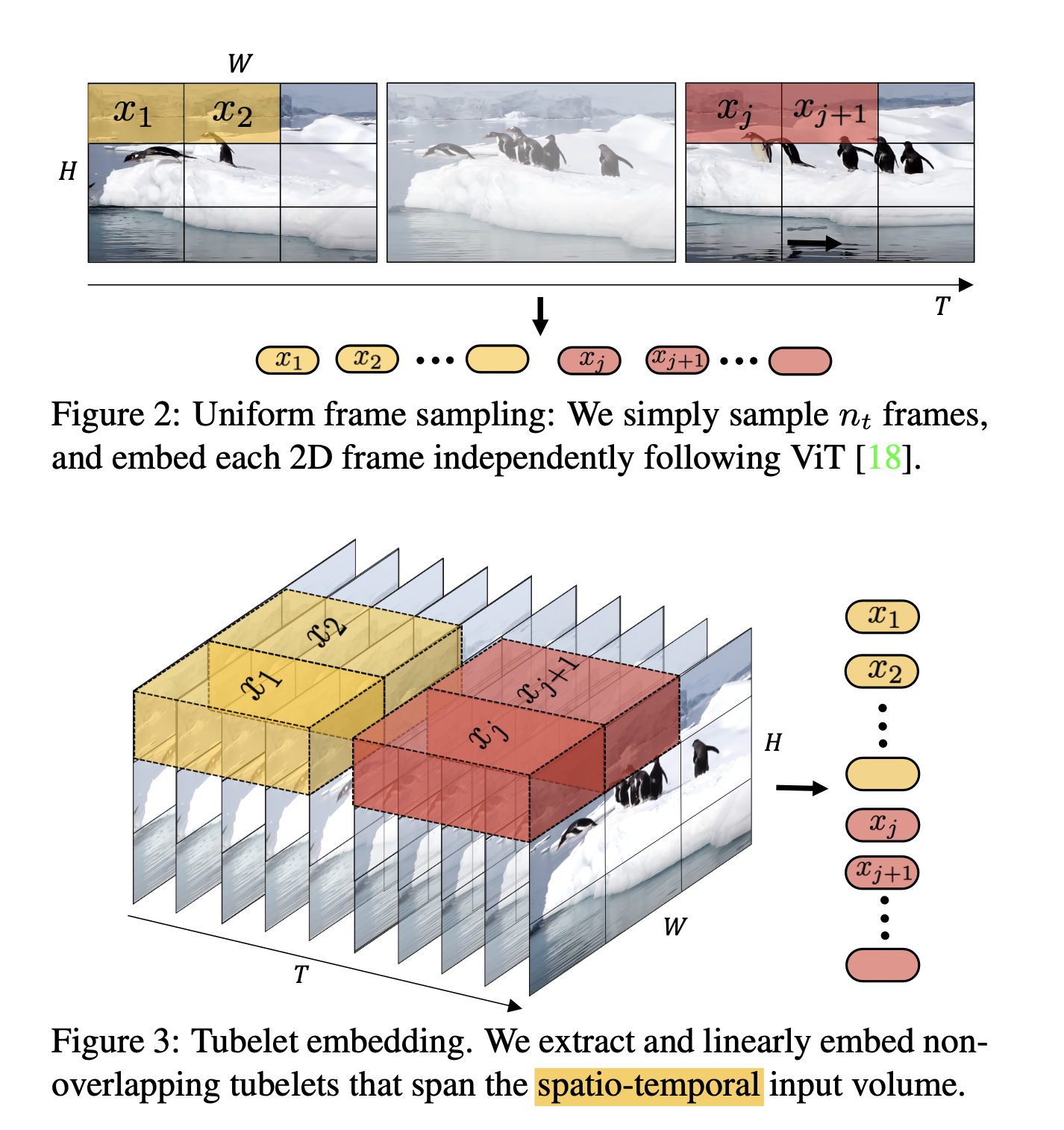
ViViT 是一种基于 Transformer 的视频分类模型,旨在利用图像分类中 Transformer 模型的成功经验来处理视频数据。该模型通过提取视频的时空(spatio-temporal)特征,并使用一系列 Transformer 层进行编码,以实现对视频内容的理解和分类。
模型结构和原理
ViViT 的核心在于将视频转换为一系列时空特征,称为时空 tokens,然后使用 Transformer 对这些 tokens 进行编码。模型考虑了两种简单的方法来将视频映射为一系列 tokens:
- 均匀帧采样(Uniform frame sampling):从输入视频片段中均匀采样帧,将每个 2D 帧独立嵌入,然后将所有 tokens 连接在一起。
- 管状嵌入(Tubelet embedding):从输入体积中提取非重叠的时空“管状”(tubelets),并将其线性投影到 tokens 上。这种方法扩展了 ViT 的嵌入到 3D,相当于 3D 卷积,可在 tokenization 过程中融合时空信息。
ViViT 提出了多种基于 Transformer 的架构变体,包括:
- 时空注意力(Spatio-temporal attention):直接将所有时空 tokens 通过 Transformer 编码器进行处理。
- 分解编码器(Factorised encoder):使用两个分开的 Transformer 编码器,首先对来自同一时间索引的 tokens 进行空间编码,然后使用时间编码器对不同时间索引的 tokens 进行建模。
- 分解自注意力(Factorised self-attention):在每个 Transformer 块内,将多头自注意力操作分解为先空间后时间的两个操作。
模型的训练过程
ViViT 的训练过程涉及以下几个方面:
- 有效正则化:为了在相对较小的数据集上有效训练模型,ViViT 实施了一系列正则化技术。
- 利用预训练图像模型:ViViT 利用预训练的图像模型来增强其学习能力,从而提高训练效率和模型性能。
- 状态艺术结果:ViViT 在多个视频分类基准测试上实现了最先进的结果,包括 Kinetics 400 和 600、Epic Kitchens、Something-Something v2 和 Moments in Time,超越了基于深度 3D 卷积网络的先前方法。
模型的推理过程
在推理阶段,ViViT 可以应用于视频分类任务,将输入视频映射为一系列时空 tokens,然后使用训练好的 Transformer 模型对这些 tokens 进行编码和分类,从而实现对视频内容的理解和分类。
ViViT的创新之处在于首次将Transformer成功引入视频领域,通过Self-Attention机制捕捉视频的时空依赖关系,优于传统CNN方法。在多个视频理解基准测试中,ViViT展现了领先的性能表现。
MAE
论文:Masked Autoencoders Are Scalable Vision Learners
链接:https://arxiv.org/abs/2111.06377
掩蔽自编码器(MAE)
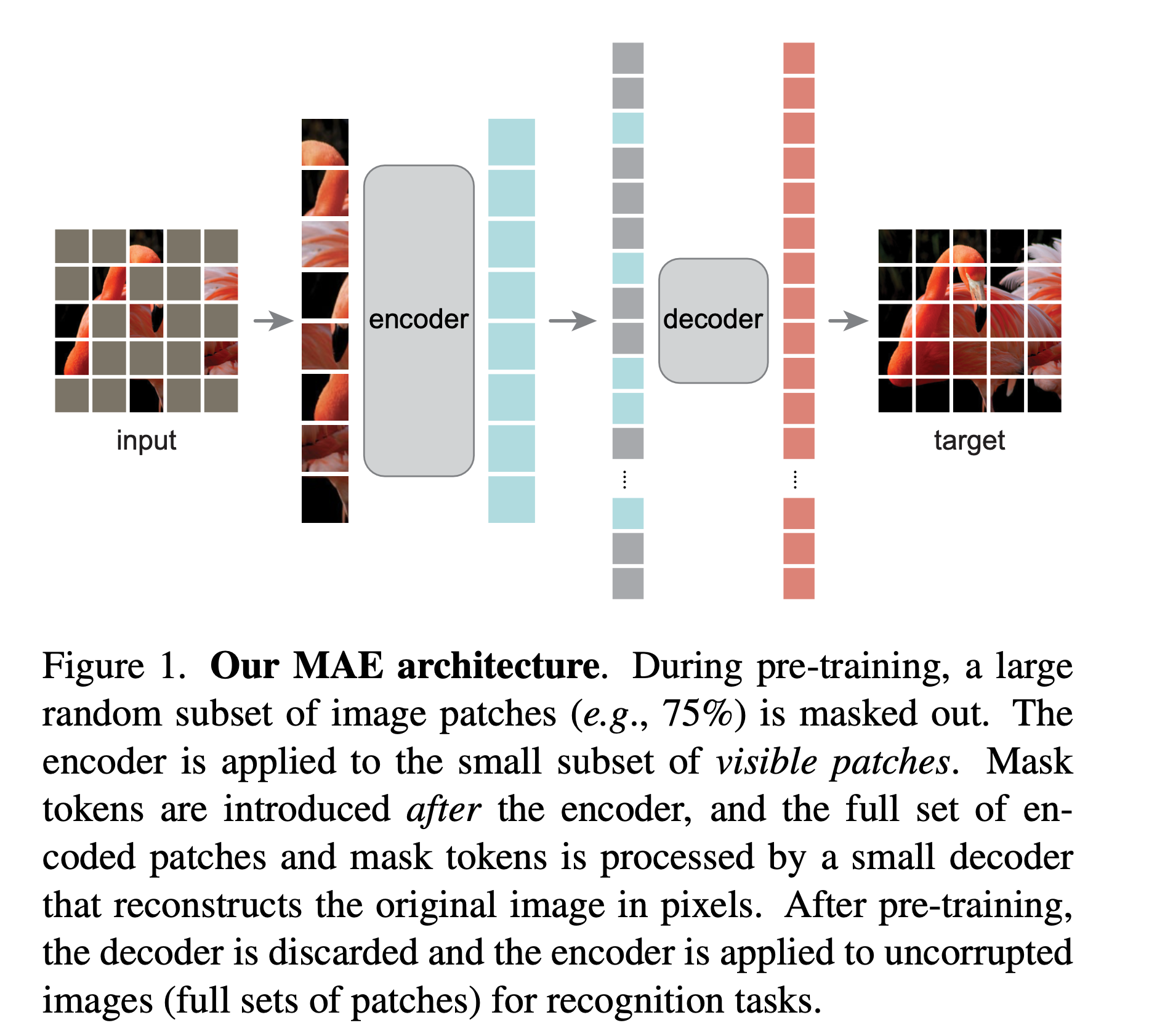
这项研究显著改进了传统的在大型数据集上的高计算成本和训练低效率,这些都与高维度和大量信息有关,它使用了一种称为掩蔽自编码器的自监督预训练方法。
具体来说,通过遮盖输入图像的部分,网络被训练以预测隐藏部分的信息,从而更有效地学习图像中重要的特征和结构,并获得丰富的视觉数据表示。这个过程使得数据的压缩和表示学习更加高效,降低了计算成本,并增强了不同类型的视觉数据和任务的通用性。
这项研究的方法也与语言模型的演变密切相关,如BERT(Bidirectional Encoder Representations from Transformers)。BERT通过掩蔽语言建模(MLM)实现了对文本数据的深层次理解,而He等人将类似的掩蔽技术应用于视觉数据,实现了对图像的更深入的理解和表示。
NaViT
论文:Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
链接:https://arxiv.org/abs/2307.06304
原生分辨率视觉变换器(NaViT)
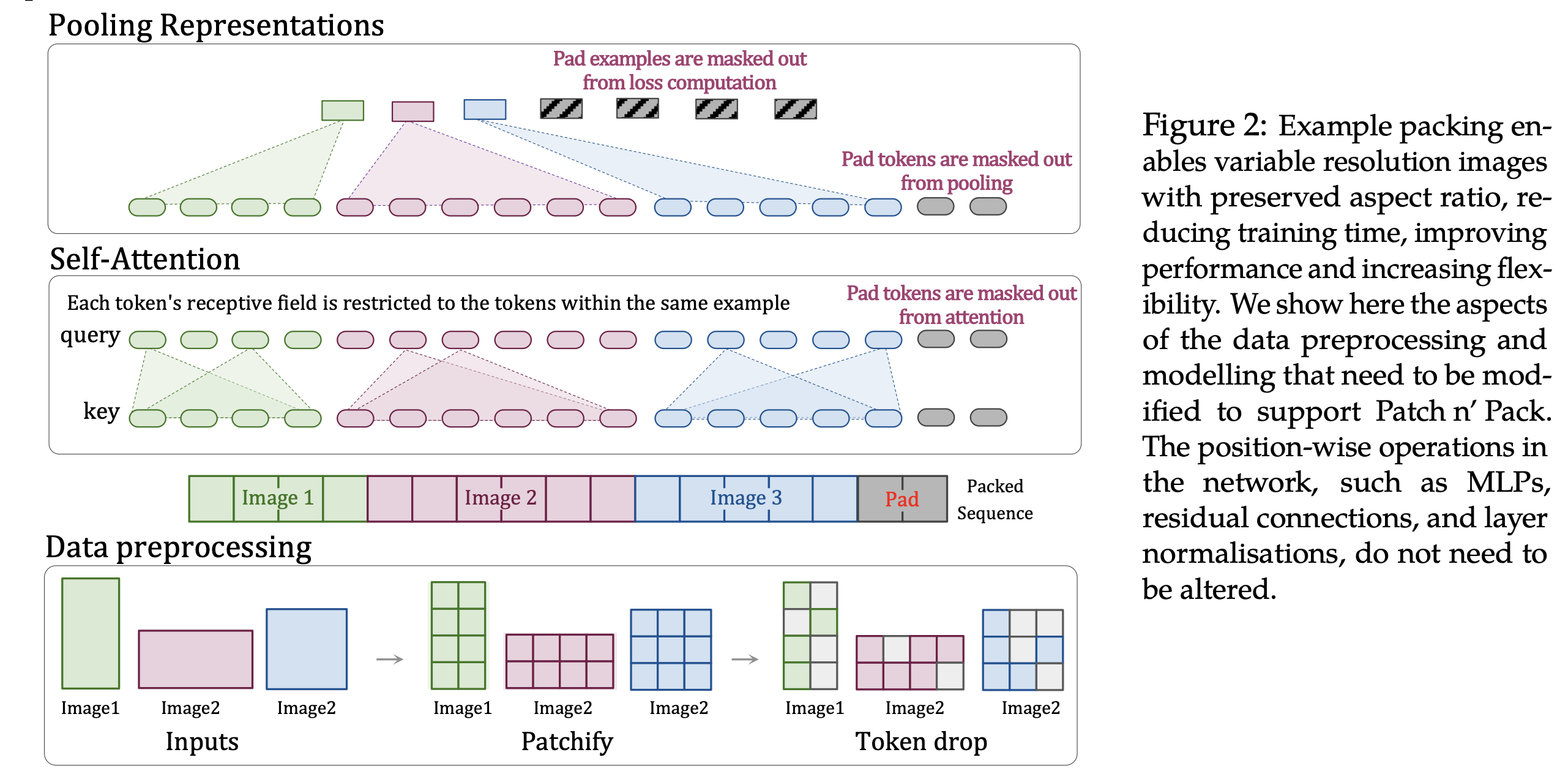
这项研究提出了原生分辨率视觉变换器(NaViT),一个旨在进一步扩展视觉变换器(ViT)应用到任何宽高比或分辨率图像的模型。
传统ViT的挑战
视觉变换器通过将图像划分为固定大小的补丁,并将这些补丁作为token,将变换器模型应用于图像识别任务,引入了一种突破性的方法。然而,这种方法假设了针对特定分辨率或宽高比优化的模型,需要对不同大小或形状的图像进行模型调整。这是一个重大的限制,因为现实世界的应用通常需要处理各种大小和宽高比的图像。
NaViT的创新
NaViT设计用于高效处理任何宽高比或分辨率的图像,允许它们直接输入模型而无需事先调整。Sora也将这种灵活性应用于视频,通过无缝处理各种大小和形状的视频和图像,显著提高了灵活性和适应性。
NaViT是一种新型的Vision Transformer模型,全称是”Naive Vision Transformer”。它的主要创新点在于能够处理任意纵横比和分辨率的图像输入,突破了之前Vision Transformer只能处理固定分辨率的限制。
模型结构
NaViT的主要模块包括:
- Patch Partition
- 将输入图像按照指定大小切分成多个Patch,并将它们映射为Patch Embeddings。
- 对于不同分辨率的图像,会生成不同数量的Patches。
- Patch Rearrangement
- 将一维序列的Patch Embeddings重新排列成二维矩阵。
- 这种排列方式使Patch之间的相对位置信息得以保留。
- Transformer Encoder
- 采用标准的Transformer Encoder架构,包括多头注意力和前馈网络。
- 通过Self-Attention学习Patch之间的上下文依赖关系。
- Classification/Detection Head
- 根据下游任务,接一个分类头或检测头。
模型原理
传统的Vision Transformer只能处理固定分辨率的图像,因为它的Patch嵌入是按照预设的网格大小切分得到的。而NaViT的创新在于:
- 采用了一种灵活的Patch分割和重排方式。
- 将一维的Patch Embeddings序列重新排列成二维矩阵。
- 这样的排列方式保留了Patch之间的相对位置关系。
- Transformer Encoder可以直接作用于这个二维矩阵,捕获不同位置Patch之间的依赖。
通过这种设计,NaViT可以自适应地处理任意分辨率和纵横比的图像输入,大大提高了其应用场景的灵活性。
Dit
论文:Scalable Diffusion Models with Transformers
链接:https://arxiv.org/abs/2212.09748
DiT利用 transformer 结构探索新的扩散模型,成功利用 transformer 替换 U-Net 主干。
- DiT 首先将每个 patch 空间表示 Latent 输入到第一层网络,以此将空间输入转换为 tokens 序列。
- 将标准基于 ViT 的 pathc 和 position embedding 应用于所有输入 token,最后将输入 token 由 transformer 处理
- DiT 还会处理额外信息,eg 时间步长、类别标签、文本语义等
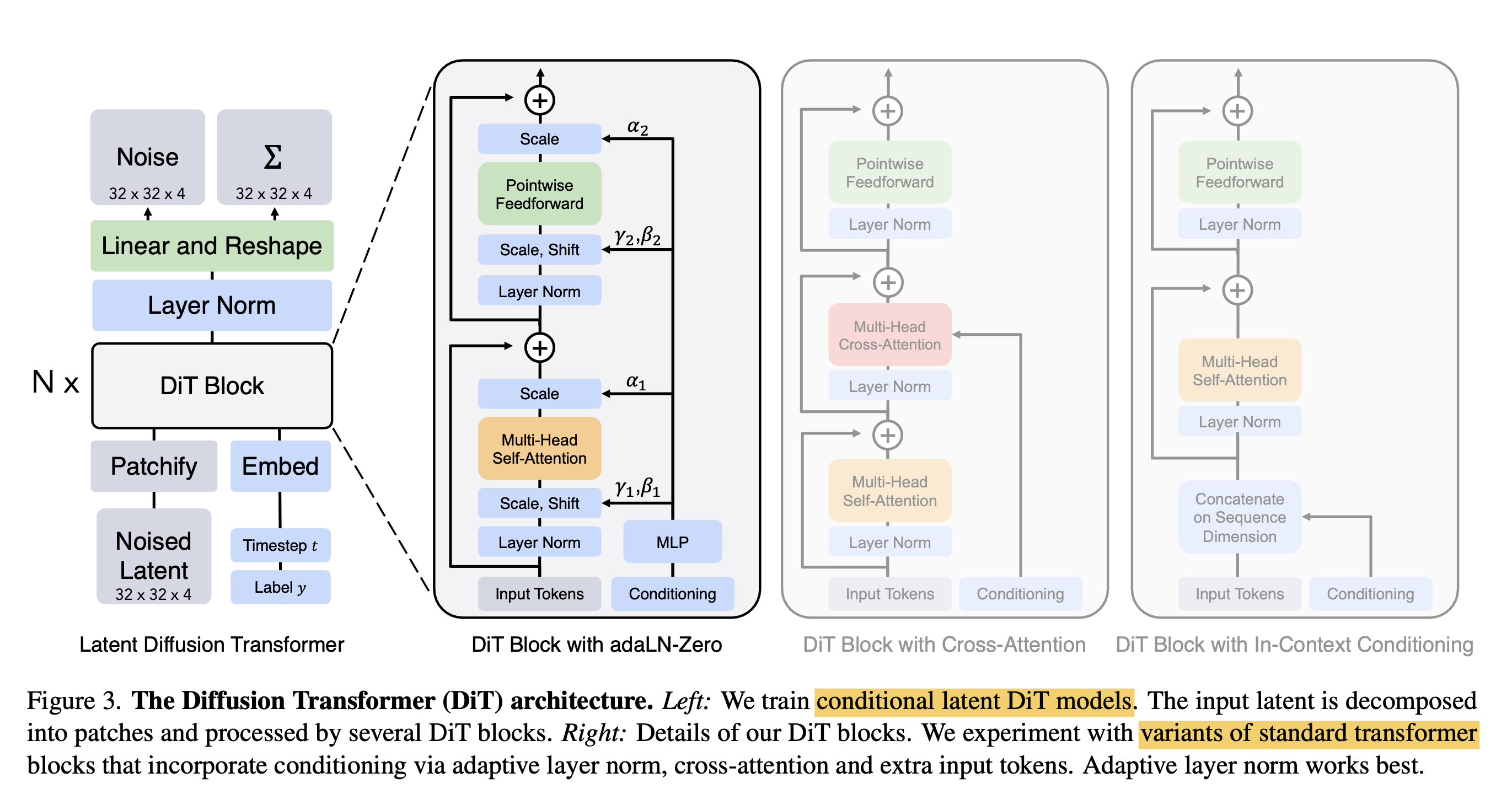
模型网络结构
DiT模型由以下几个主要组成部分
- Diffusion Module
- 负责构建Diffusion Chain,通过多次添加高斯噪声将原始数据(如图像)逐渐破坏,生成一系列噪声数据x1, x2, …xT。
- T是Diffusion Chain的最大长度(步数)。
- Transformer Encoder
- 输入是当前时刻的噪声数据xt。
- 将xt划分为一系列patches(如16x16像素区域),并映射为patch embedding序列。
- 使用标准的Transformer Encoder模块,通过Self-Attention捕捉patch之间的长程依赖关系。
- Prediction Head:
- 输入是Transformer Encoder的输出表示。
- 通过一个前馈网络(FNN)层,预测出当前时刻的”去噪”方向,即从xt到xt-1的变化。
- 重建模块:
- 通过累计预测的去噪方向,从纯噪声xT重建出最终的干净数据x0。
模型作用:
- Diffusion Module负责构造出从原始数据到噪声的过程,为训练提供监督信号。
- Transformer Encoder捕捉输入数据(如图像)的局部和全局上下文信息。
- Prediction Head根据Transformer输出,预测每一步正确的去噪方向。
- 重建模块通过迭代去噪过程,最终从噪声中生成出高质量的数据(如图像)。
训练过程:
- 构建Diffusion Chain,从真实数据x0出发,通过多次添加噪声生成噪声数据序列{x1, x2, …xT}。
- 以(xt, xt-1)作为训练样本对,其中xt为输入,xt-1是标签(真实去噪目标)。
- 输入xt到Transformer Encoder,得到其表示。
- 通过Prediction Head预测噪声xt->xt-1的去噪方向。
- 计算预测值与真实标签xt-1的误差损失函数。
- 基于损失函数,使用优化器(如Adam)对全部模型参数进行更新。
- 重复以上过程,使模型逐步学会从噪声中恢复出原始数据。
推理(生成)过程:
- 从纯噪声xT开始。
- 将xT输入到Transformer Encoder获取表示。
- Prediction Head基于该表示预测第一步去噪方向,得到xT-1。
- 重复上述过程,每次将预测的xt-1输入,累积预测去噪方向。
- 经过T步去噪,最终从xT到达目标数据x0。
总的来说,DiT模型以Diffusion Module为基础,引入Transformer Encoder捕捉输入数据的上下文,通过Prediction Head学习去噪方向,最终可以从噪声中生成高质量的数据。它结合了扩散模型和Transformer两者的优势,展现了出色的生成性能。
该模型不仅可用于图像生成,也可应用于其他连续数据如语音、视频等生成任务,体现了良好的通用性和可扩展性。论文中给出了大量分析和实验结果,解释了该模型的有效性。
文档信息
- 本文作者:huzixia
- 本文链接:https://huzixia.github.io/2024/03/09/sora-detail/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)