
解读 文生图技术栈,根据文生图的发展路线,我们把文生图的发展历程发展成如下4个阶段: 1. 基于生成对抗网络的(GAN)模型 2. 基于自回归(Autoregressive)模型 3. 基于扩散(diffusion)模型 4. 基于Transformers的扩散(diffusion)模型。
#! https://zhuanlan.zhihu.com/p/685474331
文生图技术栈
目录: [toc]
什么是文生图呢,下面这张图给了一个例子,输入文本“一只戴着太阳镜的小松鼠在演奏吉他”,经过文生图的模型,可以输出对应的一张rgb的图像。
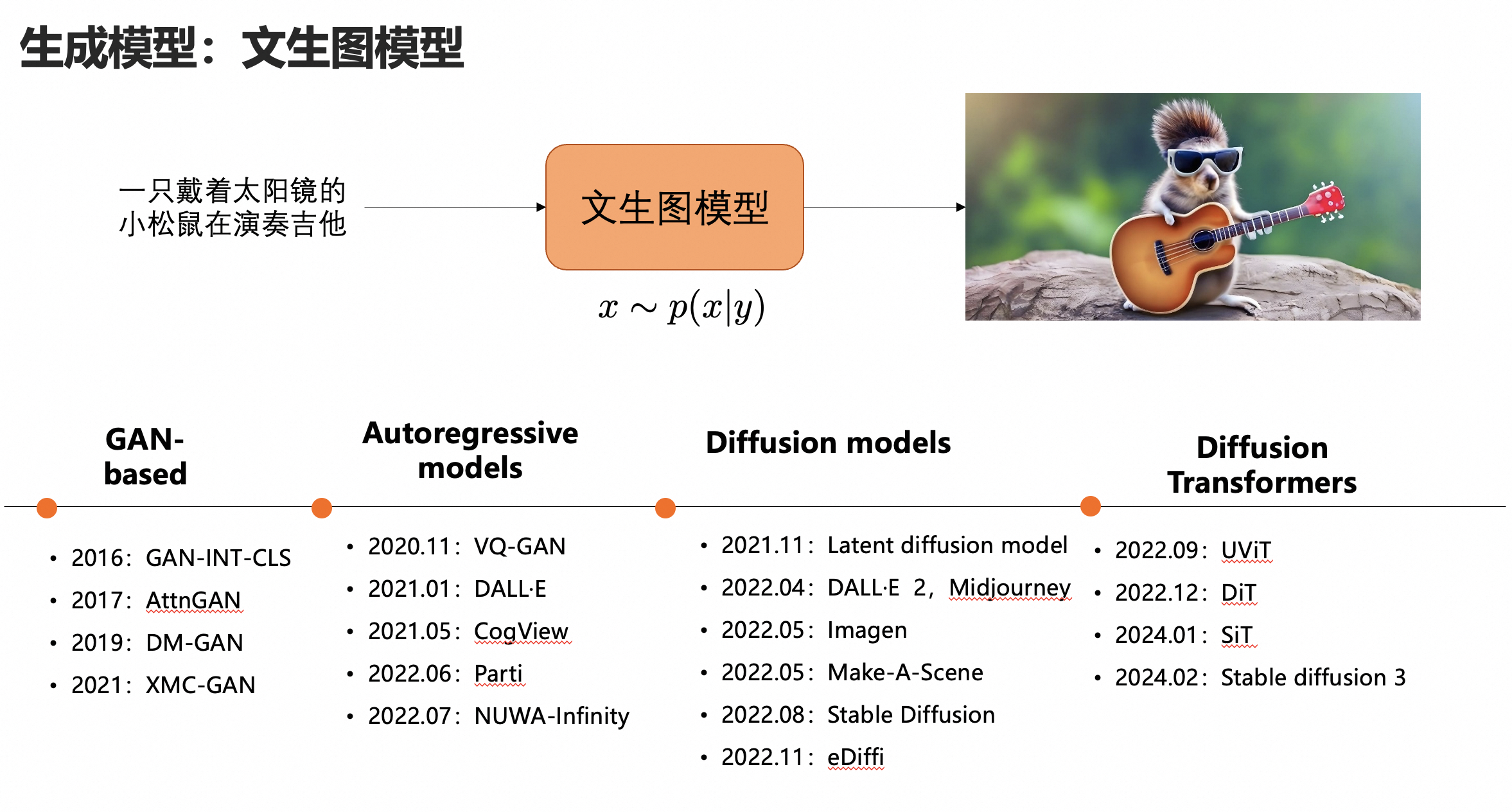
根据文生图的发展路线,我们把文生图的发展历程发展成如下4个阶段:
基于生成对抗网络的(GAN)模型
基于自回归(Autoregressive)模型
基于扩散(diffusion)模型
基于Transformers的扩散(diffusion)模型
下面我们对这四种算法模型进行简单的介绍:
1. 基于生成对抗网络的(GAN)模型
生成对抗网络的基本原理可以看左侧的示意图。
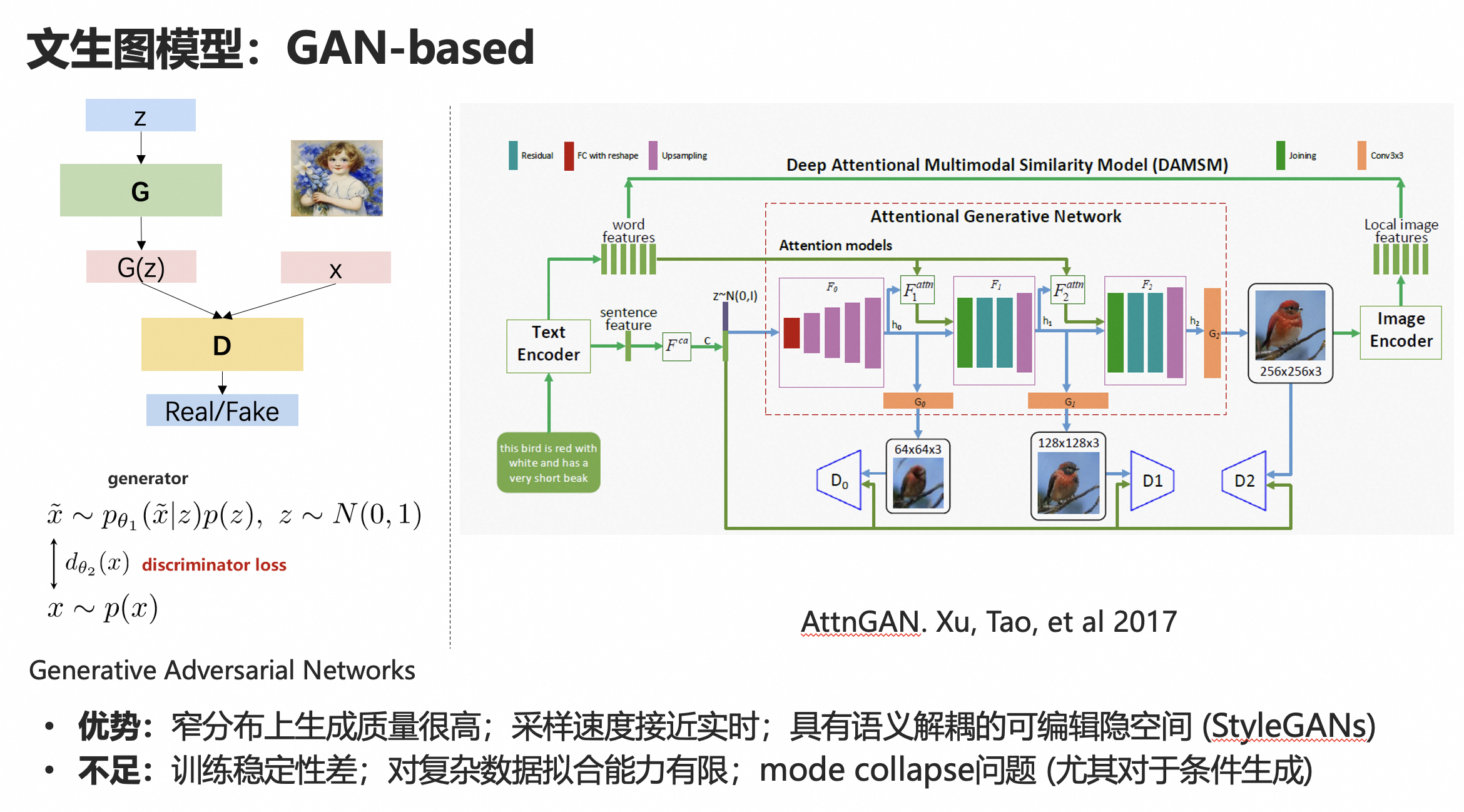
2014 年,Ian J.Goodfellow 提出了 GAN,它是由一个生成器G和一个判别器D组成。生成网络产生「假」数据,并试图欺骗判别网络;训练的时候,判别网络对生成数据进行真伪鉴别,试图正确识别所有「假」数据。在训练迭代的过程中,两个网络持续地进化和对抗,直到达到平衡状态。
推理的时候,只要保留生成器G就行了,输入一个随机噪声vector,生成一张图像。
右侧是一个经典的AttnGAN的框架,是一个引入了attention结构(使得图片生成局部能够和文本描述更加匹配)、并且从粗粒度到细粒度coarse to fine进行生成的框架,在当时还是取得了不错的生成效果。
GAN的优势是在一些窄分布(比如人脸)数据集上效果很好,采样速度快,方便嵌入到一些实时应用里面去。
缺点是比较难训练、不稳定,而且有Mode Collapse(模式崩塌)等问题。
2. 基于自回归方式的模型
第二种方法是自回归方式,自回归方式在自然语言中用的比较多,像大家听到最多的比如GPT系列。
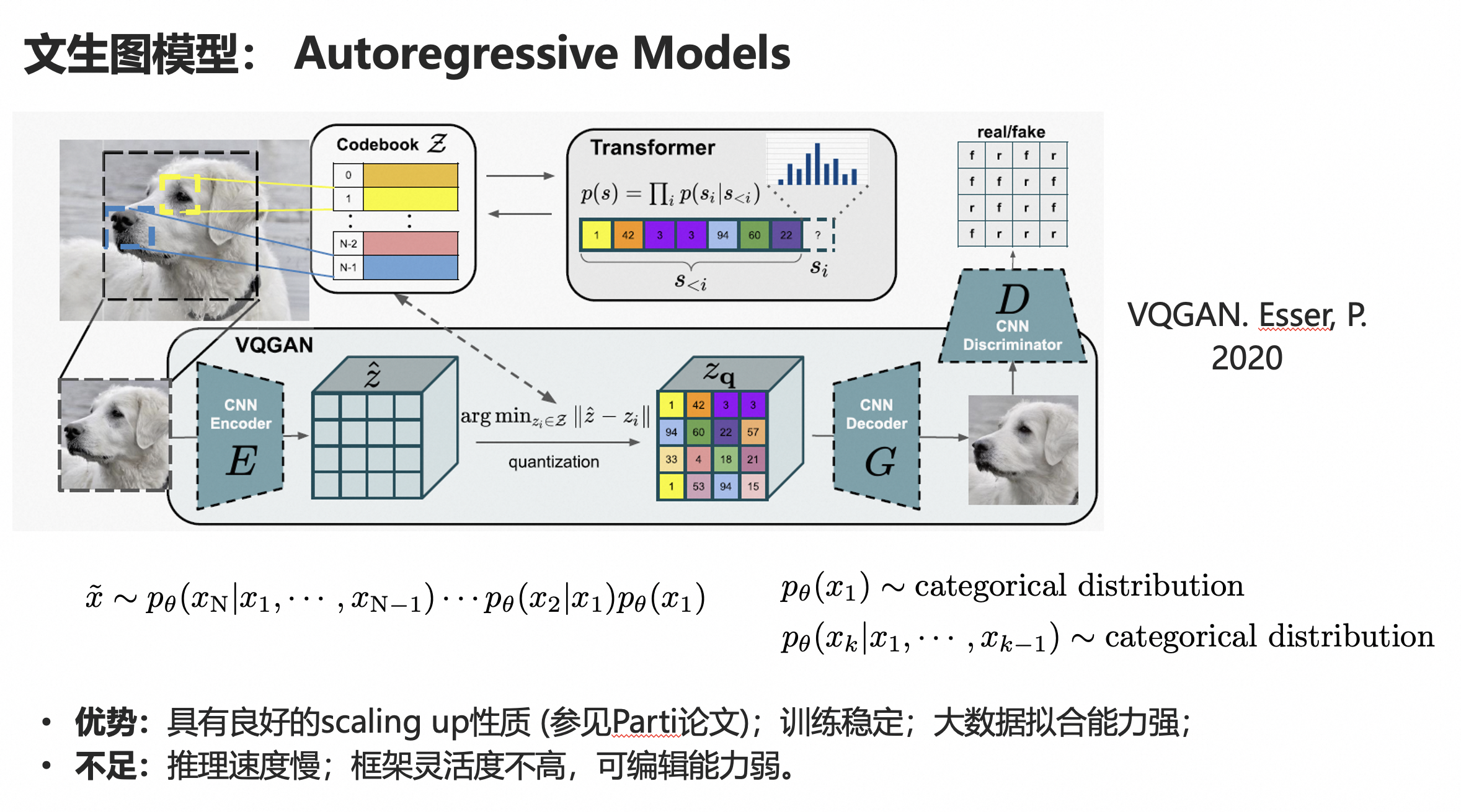
VQGAN是将类似的思路拓展到了视觉生成领域。他主要包括两个步骤:
第一步:将原始的RGB图像通过vqvae或者vqgan 离散压缩成一系列的 视觉code,这些视觉code 可以利用一个训练得到的decoder恢复出原始的图像信息,当然会损失一些细节,但整体恢复质量还是OK的,特别是加了GAN loss的。
第二步:利用transformer或者GPT,来按照一定的顺序,逐个的去预测每个视觉code,当所有code都预测完了之后,就可以用第一步训练好的Decoder来生成对应的图像。因为每个code预测过程是有随机采样的,因此可以生成多样性比较高的不同图像。
这个方法比较出名的就是VQGAN,还有就是openai的dalle。
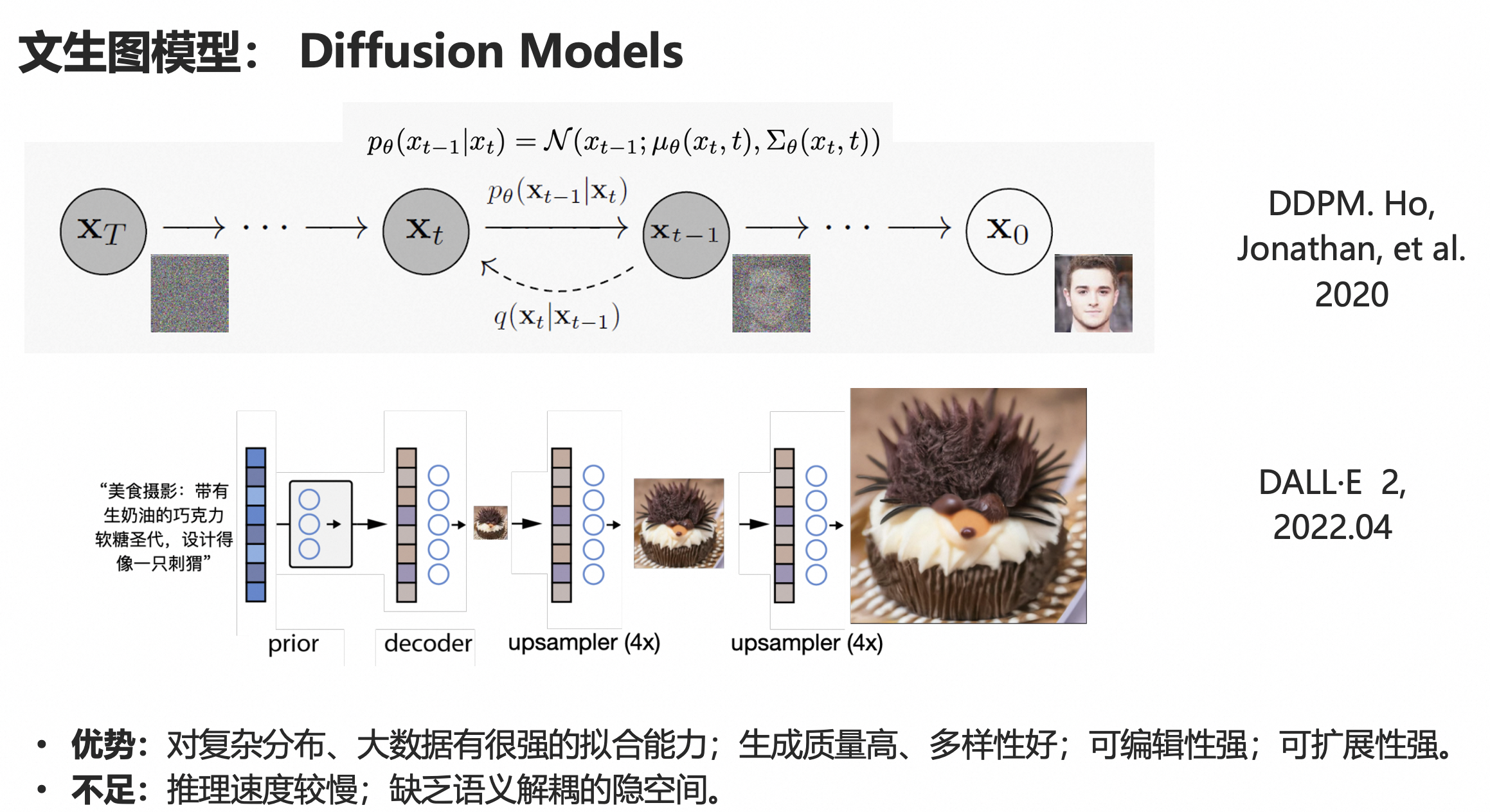
3. 基于扩散(diffusion)方式的模型
扩散模型也就是我们目前大多数文生图模型所采用的技术。
扩散模型也分为两个过程,一个是前向过程,通过向原始数据不断加入高斯噪声来破坏训练数据,最终加噪声到一定步数之后,原始数据信息就完全被破坏,无限接近与一个纯噪声。另外一个过程是反向过程,通过深度网络来去噪,来学习恢复数据。
训练完成之后,我们可以通过输入随机噪声,传递给去噪过程来生成数据。这就是DDPM的基本原理。
图中是DALLE2的一个基本框架,他的整个pipeline稍微有些复杂,输入文本,经过一个多模态的CLIP模型的文本编码器,
学习一个prior网络,生成clip 图像编码,然后decoder到64*64小图,再经过两个超分网络到256*256,再到1024*1024。
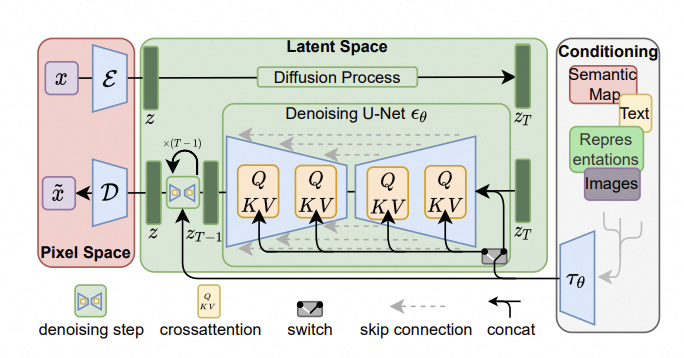
LDM原理图:
4. 基于Transformers的架构的Diffusion模型
基于Transformers的架构的Diffusion模型设计了一个简单而通用的基于Vision Transformers(ViT)的架构(U-ViT),替换了latent diffusion model中的U-Net部分中的卷积神经网络(CNN),用于diffusion模型的图像生成任务。
遵循Transformers的设计方法,这类方式将包括时间、条件和噪声图像patches在内的所有输入都视作为token。
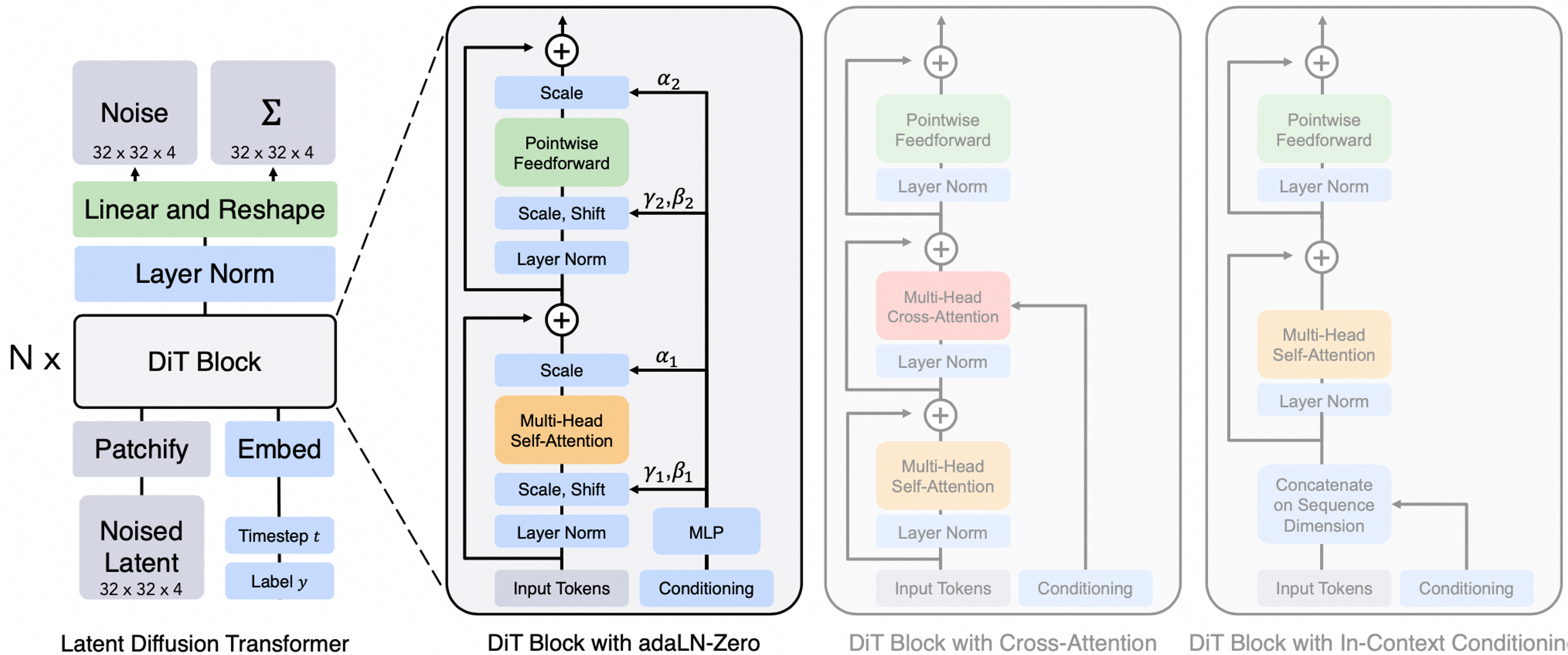
推理链路:
第一步:输入一张256x256x3的图片,经过Encoder后得到对应的latent,压缩比为8,latent space推理时输入32x32x4的噪声,将latentspace的输入token化,图片使用patchify,label和timestep使用embedding。
第二步:结合当前的step t , 输入label y, 经过N个Dit Block通过 MLP进行输出,得到输出的噪声以及对应的协方差矩阵
第三步:经过T个step采样,得到32x32x4的降噪后的latent
在训练时,需要使得去躁后的latent和第一步得到的latent尽可能一致
文档信息
- 本文作者:huzixia
- 本文链接:https://huzixia.github.io/2024/03/05/image/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)