
解读 NLP经典之作 — Bert:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练语言模型,由Google在2018年提出。它是一种基于Transformer的模型,可以用于自然语言处理(NLP)任务,如文本分类、命名实体识别、问答系统等。主要包括 1. Language Model Embedding,2. Bert 模型解读,3. Bert fine-tuning,4. Bert 代码实现等方面。
#! https://zhuanlan.zhihu.com/p/683632236
解读 NLP经典之作 — Bert
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练语言模型,由Google在2018年提出。它是一种基于Transformer的模型,可以用于自然语言处理(NLP)任务,如文本分类、命名实体识别、问答系统等。
论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
链接:https://arxiv.org/abs/1810.04805
github:https://github.com/google-research/bert
目录: [toc]
1. Language Model Embedding
背景是语言模型来辅助NLP任务已经得到了学术界较为广泛的探讨,通常有两种方式:
- feature-based
- fine-tuning
1.1 Feature-based方法
Feature-based指利用语言模型的中间结果也就是LM embedding, 将其作为额外的特征,引入到原任务的模型中,例如在TagLM[1]中,采用了两个单向RNN构成的语言模型,将语言模型的中间结果
\[h_i^{L M}=\left[\overrightarrow{h_i^{L M}} ; \overleftarrow{h_i^{L M}}\right]\]引入到序列标注模型中,如下图1所示,其中左边部分为序列标注模型,也就是task-specific model,每个任务可能不同,右边是前向LM(Left-to-right)和后向LM(Right-To-Left), 两个LM的结果进行了合并,并将LM embedding与词向量、第一层RNN输出、第二层RNN输出进行了concat操作。
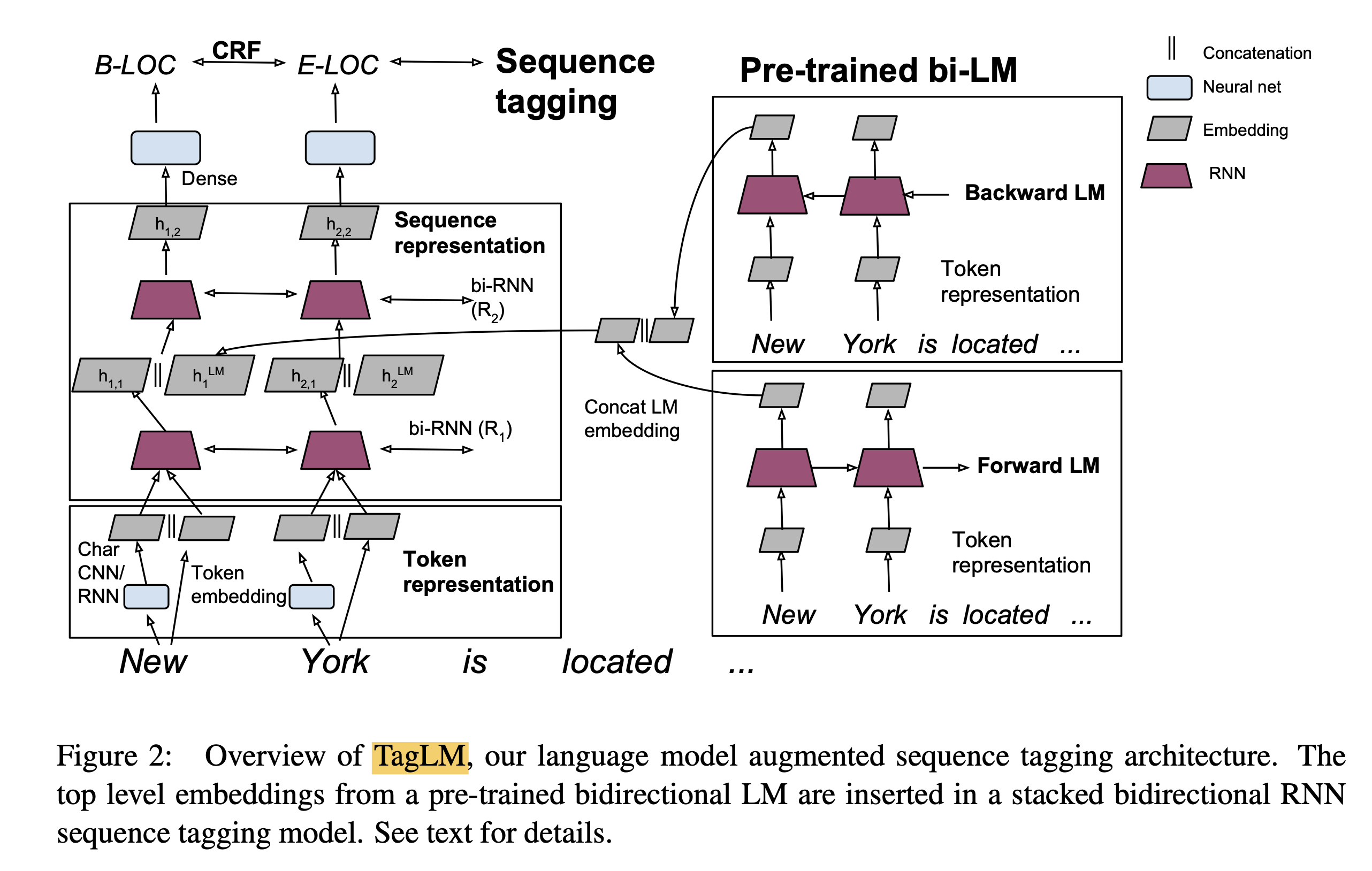
通常feature-based方法包括两步:
- 首先在大的语料A上无监督地训练语言模型,训练完毕得到语言模型。
- 然后构造task-specific model例如序列标注模型,采用有标记的语料B来有监督地训练task-sepcific model,将语言模型的参数固定,语料B的训练数据经过语言模型得到LM embedding,作为task-specific model的额外特征。
1.2 Fine-tuning方法
Fine-tuning方式是指在已经训练好的语言模型的基础上,加入少量的task-specific parameters, 例如对于分类问题在语言模型基础上加一层softmax网络,然后在新的语料上重新训练来进行fine-tune。
例如OpenAI GPT [3] 中采用了这样的方法,模型如下所示
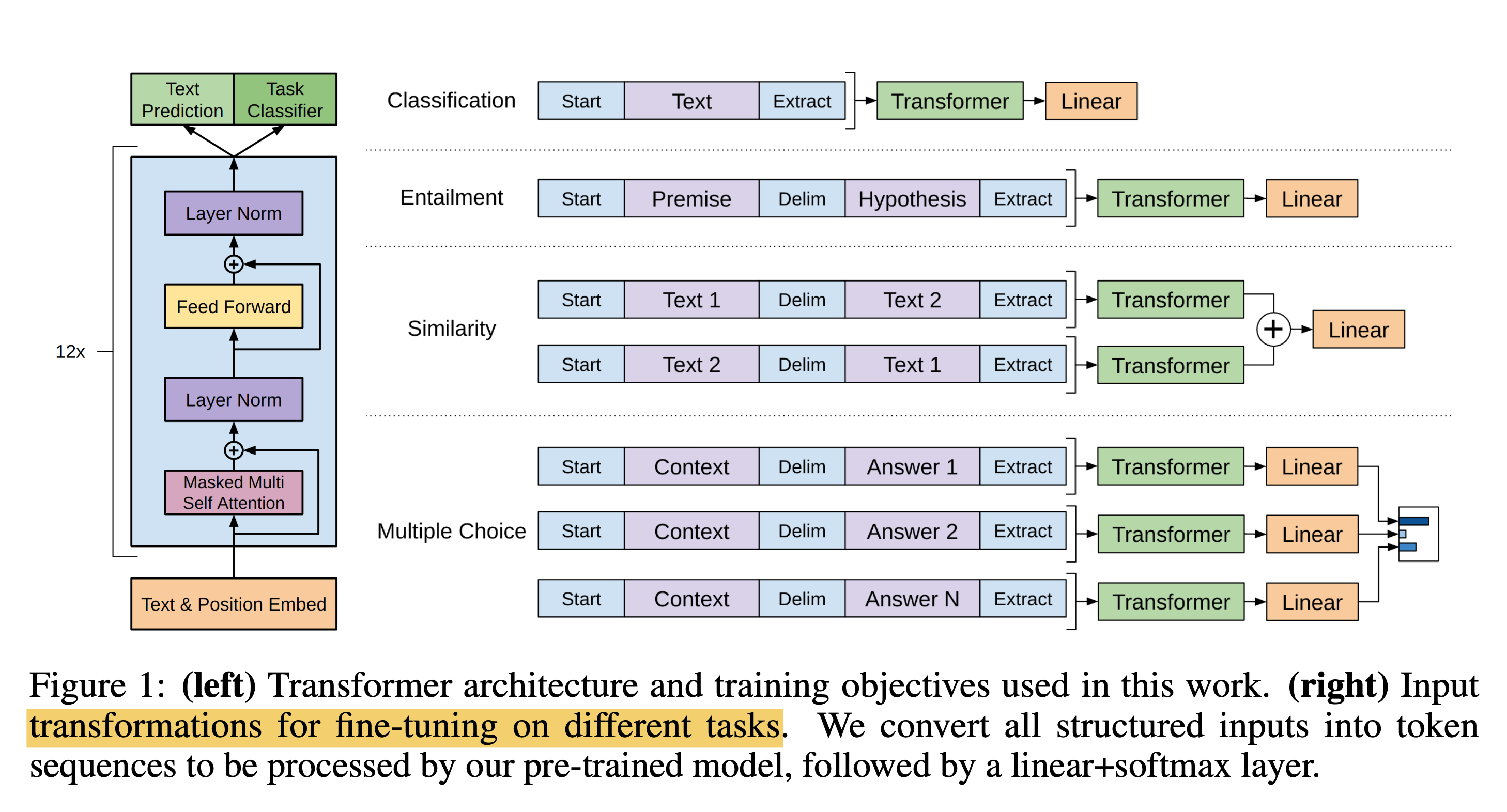
首先语言模型采用了Transformer Decoder的方法来进行训练,采用文本预测作为语言模型训练任务,训练完毕之后,加一层Linear Project来完成分类/相似度计算等NLP任务。
因此总结来说,LM + Fine-Tuning的方法工作包括两步:
- 构造语言模型,采用大的语料A来训练语言模型。
- 在语言模型基础上增加少量神经网络层来完成specific task例如序列标注、分类等,然后采用有标记的语料B来有监督地训练模型,这个过程中语言模型的参数并不固定,依然是trainable variables。
而BERT论文采用了LM + fine-tuning的方法,同时也讨论了BERT + task-specific model的方法。
2. Bert 模型解读
2.1 BERT与GPT ELMo关系
BERT是基于GPT和ELMo这两个工作的。
BERT与GPT的区别:
- 在2018年,GPT是单向的,基于左边的上下文信息,来生成新的文段。(2023年有待考究);
- 而BERT不仅用了左侧的信息,还用了右侧的信息,所以说是一个双向的操作,即Bidirectional。
BERT与ELMo的区别:
- ELMo用的是基于RNN的架构,在用于一些特定的下游任务时,需要对架构做一定的调整;
- BERT用的是Transformer,只需要改最上层的就行了,这里指的是BERT的那个额外的输出层。
之前语言模型的问题在于,没有同时利用到Bidirectional信息,现有的语言模型例如ELMo号称是双向LM(BiLM),但是实际上是两个单向RNN构成的语言模型的拼接,如下图所示:
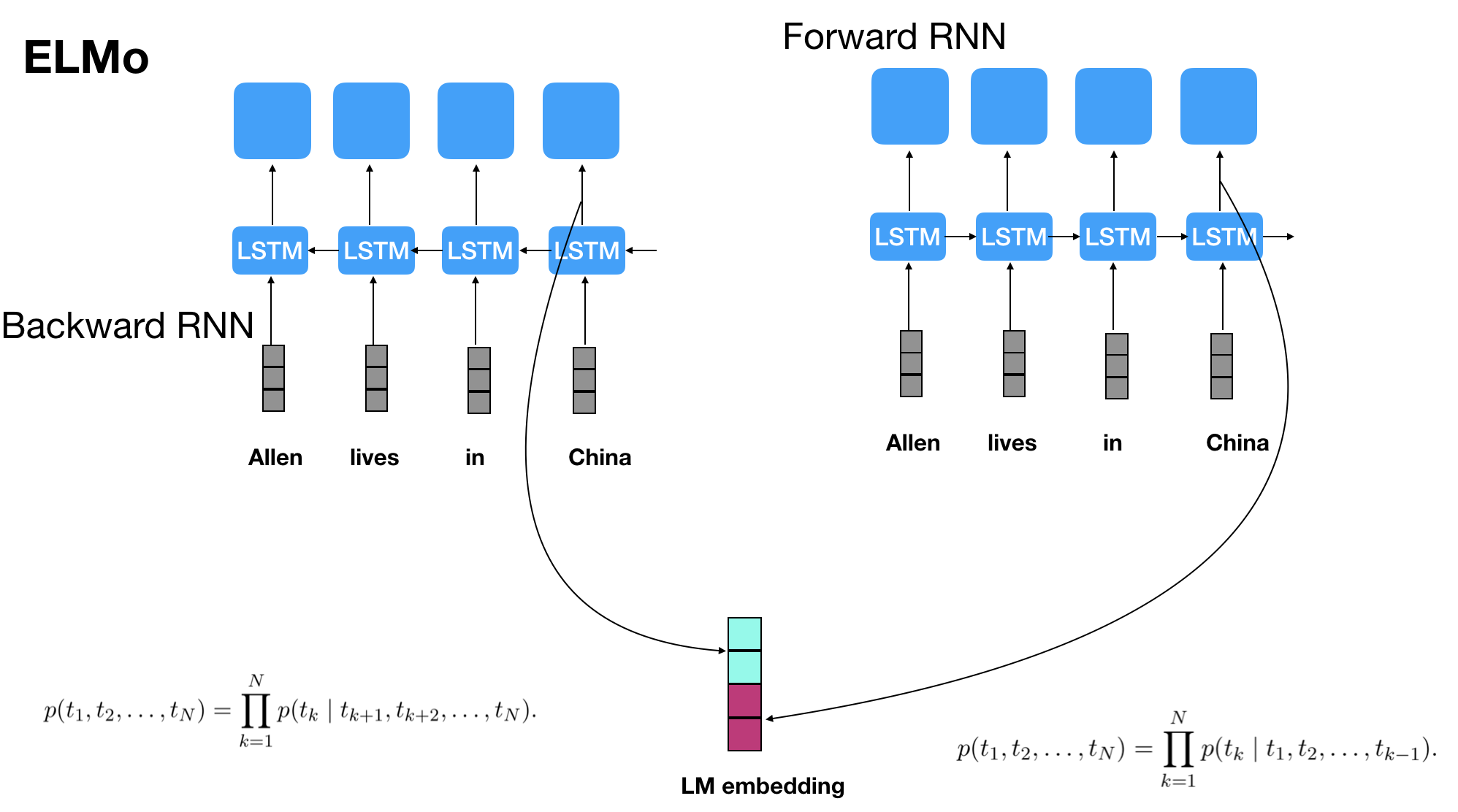
因为语言模型本身的定义是计算句子的概率: \(\begin{aligned} p(S)=p\left(w_1, w_2,\right. & \left.w_3, \ldots, w_m\right)=p\left(w_1\right) p\left(w_2 \mid w_1\right) p\left(w_3 \mid w_1, w_2\right) \ldots \\ & \cdot p\left(w_m \mid w_1, w_2, \ldots, w_{m-1}\right) \\ = & \prod_{i=1}^m p\left(w_i \mid w_1, w_2, \ldots, w_{i-1}\right) \end{aligned}\)
前向RNN构成的语言模型计算的是: \(p\left(w_1, w_2, w_3, \ldots, w_m\right)=\prod_{i=1}^m p\left(w_i \mid w_1, w_2, \ldots, w_{i-1}\right)\)
也就是当前词的概率只依赖前面出现词的概率。
而后向RNN构成的语言模型计算的是: \(p\left(w_1, w_2, w_3, \ldots, w_m\right)=\prod_{i=1}^m p\left(w_i \mid w_{i+1}, w_{i+2}, \ldots, w_m\right)\)
也就是当前词的概率只依赖后面出现的词的概率。
那么如何才能同时利用好前面词和后面词的概率呢?
BERT提出了Masked Language Model,也就是随机去掉句子中的部分token,然后模型来预测被去掉的token是什么。这样实际上已经不是传统的神经网络语言模型(类似于生成模型)了,而是单纯作为分类问题,根据这个时刻的hidden state来预测这个时刻的token应该是什么,而不是预测下一个时刻的词的概率分布了。
2.2 Masked Language Model
Maked LM 是为了解决单向信息问题,现有的语言模型的问题在于,没有同时利用双向信息,如 ELMO 号称是双向LM,但实际上是两个单向 RNN 构成的语言模型的拼接,由于时间序列的关系,RNN模型预测当前词只依赖前面出现过的词,对于后面的信息无从得知。
那么如何同时利用好前面的词和后面的词的语义呢?
- Bert 提出 Masked Language Model,也就是随机遮住句子中部分 Token,模型再去通过上下文语义去预测 Masked 的词,通过调整模型的参数使得模型预测正确率尽可能大。
- 怎么理解这一逻辑,Bert 预训练过程就是模仿我们学习语言的过程,要准确的理解一个句子或一段文本的语义,就要学习上下文关系,从上下文语义来推测空缺单词的含义。
- 而 Bert 的做法模拟了英语中的完形填空,随机将一些单词遮住,让 Bert 模型去预测这个单词,以此达到学习整个文本语义的目的。
那么 Bert 如何做到 “完形填空” 的呢?
随机 mask 预料中 15% 的 Token,然后预测 [MASK] Token,与 masked token 对应的最终隐藏向量被输入到词汇表上的 softmax 层中。
这虽然确实能训练一个双向预训练模型,但这种方法有个缺点,因为在预训练过程中随机 [MASK] Token 由于每次都是全部 mask,预训练期间会记住这些 MASK 信息,但是在fine-tune期间从未看到过 [MASK] Token,导致预训练和 fine-tune 信息不匹配。
而为了解决预训练和 fine-tune 信息不匹配,Bert 并不总是用实际的 [MASK] Token 替换 masked 词汇。

my dog is hairy → my dog is [MASK] 80%选中的词用[MASK]代替
my dog is hairy → my dog is apple 10%将选中的词用任意词代替
my dog is hairy → my dog is hairy 10%选中的词不发生变化
为什么 15% 的 Token 不完全 MASK?如果只有 MASK,这个预训练模型是有偏置的,也就是只能学到一种方式,用上下文去预测一个词,这导致 fine-tune 丢失一部分信息。
加上 10% 的随机词和 10% 的真实值是让模型知道,每个词都有意义,除了要学习上下文信息,还需要提防每个词,因为每个词都不一定是对的,对于 Bert 来说,每个词都需要很好的理解和预测。
有些人会疑惑,加了随机 Token,会让模型产生疑惑,从而不能学到真实的语义吗?
- 对于人来说,完形填空都不一定能做对,而将文本中某些词随机替换,更是难以理解,从概率角度来说,随机 Token 占比只有 15% * 10% = 1.5%,预料足够的情况下,这并不会影响模型的性能。
- 让模型去预测/恢复被掩盖的那些词语。最后在计算损失时,只计算被掩盖的这些Tokens(也就是掩盖的那15%的Tokens)。
因为 [MASK] Token 占比变小,且预测难度加大的原因,所以 MASK 会花更多时间。
2.3 Next Sentence Prediction
在许多下游任务中,如问答系统 QA 和自然语言推理 NLI,都是建立在理解两个文本句子之间的关系基础上,这不是语言模型能直接捕捉到的。
为了训练一个理解句子关系的模型,作者提出 Next Sentence Prediction,也即是预训练一个下一句预测的二分类任务,这个任务就是每次训练前都会从语料库中随机选择句子 A 和句子 B,50% 是正确的相邻的句子,50% 是随机选取的一个句子,这个任务在预训练中能达到 97%-98% 的准确率,并且能很显著的提高 QA 和 NLI 的效果。
为了预测第二个句子是否确实是第一个句子的后续句子,执行以下步骤:
- 整个输入序列的embedding被送入Transformer 模型
- [CLS]对应的输出经过简单MLP分类层变成2*1向量([isNext,IsnotNext])
- 用softmax计算IsNext的概率

Input = [CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP]
penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
模型通过对 Masked LM 任务和 Next Sentence Prediction 任务进行联合训练,使模型输出的每个字 / 词的向量表示都能尽可能全面、准确地刻画输入文本(单句或语句对)的整体信息,为后续的微调任务提供更好的模型参数初始值。
论文中说该分类模型达到 97%-98%的准确率。注意:
- Masked LM 是捕捉词之间的关系
- Next Sentence Prediction 是捕捉句子之间的关系
- Masked LM 和 Next Sentence Prediction 是放在一起训练的
2.4 Bert 输入表征
Bert 的输入相较其它模型,采用了三个 Embedding 相加的方式,通过加入 Token Embeddings,Segment Embeddings,Position Embeddings 三个向量,以此达到预训练和预测下一句的目的。
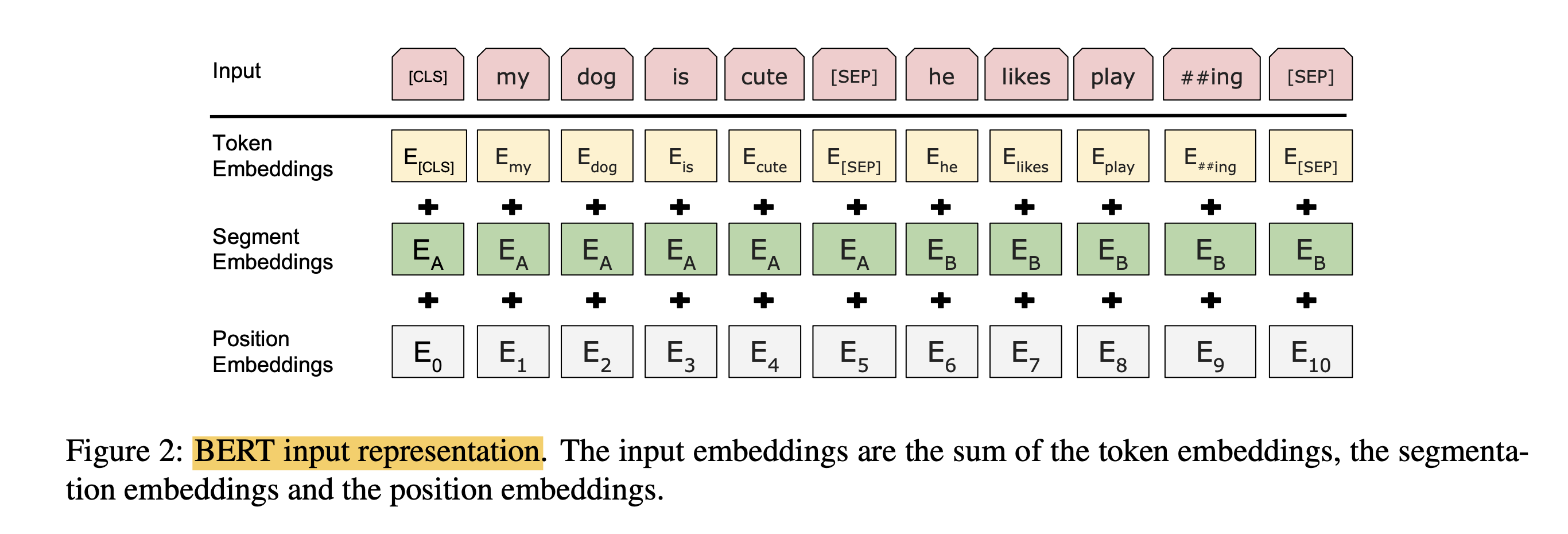
Bert 的输入 Input 是两个句子:”my dog is cute”,”he likes playing”。首先会在第一句开头加上特殊Token [CLS] 用于标记句子开始,用 [SEP] 标记句子结束。
特殊字符介绍:
[CLS],全称是Classification Token(CLS),是用来做一些「分类」任务。[CLS] token为什么会放在第一位?因为本身BERT是并行结构, [CLS]放在尾部也可以,放在中间也可以。放在第一个应该是比较方便。
[SEP],全称是Special Token(SEP),是用来区分两个句子的,因为通常在train BERT的时候会输入两个句子。从上面图片中,可以看出SEP是区分两个句子的token。
然后对每个 Token 进行 3 个 Embedding,词的 Embedding (Token Embeddings),位置 Embedding (Position Embeddings),句子 Embedding (Segment Embeddings)。最终将三个 Embedding 求和的方式输入到下一层。
下面详细介绍下三个 Embedding:
Token Embeddings
通过建立字向量表将每个字转换成一个一维向量,作为模型输入。特别的,英文词汇会做更细粒度的切分,比如playing 或切割成 play 和 ##ing,中文目前尚未对输入文本进行分词,直接对单子构成为本的输入单位。将词切割成更细粒度的 Word Piece 是为了解决未登录词的常见方法。
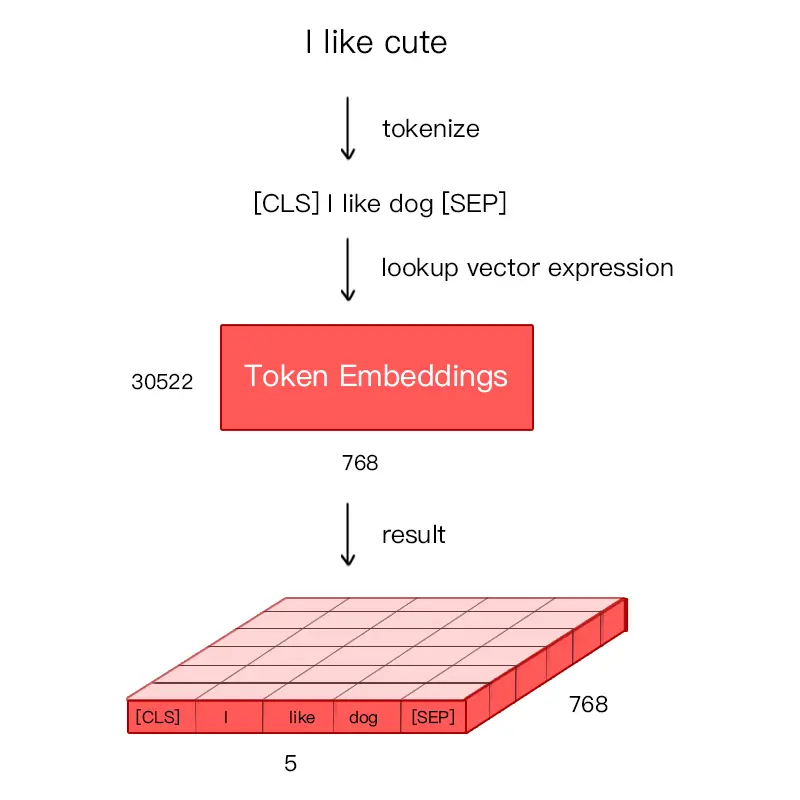
假如输入文本 “I like dog”。下图则为 Token Embeddings 层实现过程。输入文本在送入 Token Embeddings 层之前要先进性 tokenization 处理,且两个特殊的 Token 会插入在文本开头 [CLS] 和结尾 [SEP]。
Bert 在处理英文文本时只需要 30522 个词,Token Embeddings 层会将每个词转换成 768 维向量,例子中 5 个Token 会被转换成一个 (5, 768) 的矩阵或 (1, 5, 768) 的张量。
Segment Embedding
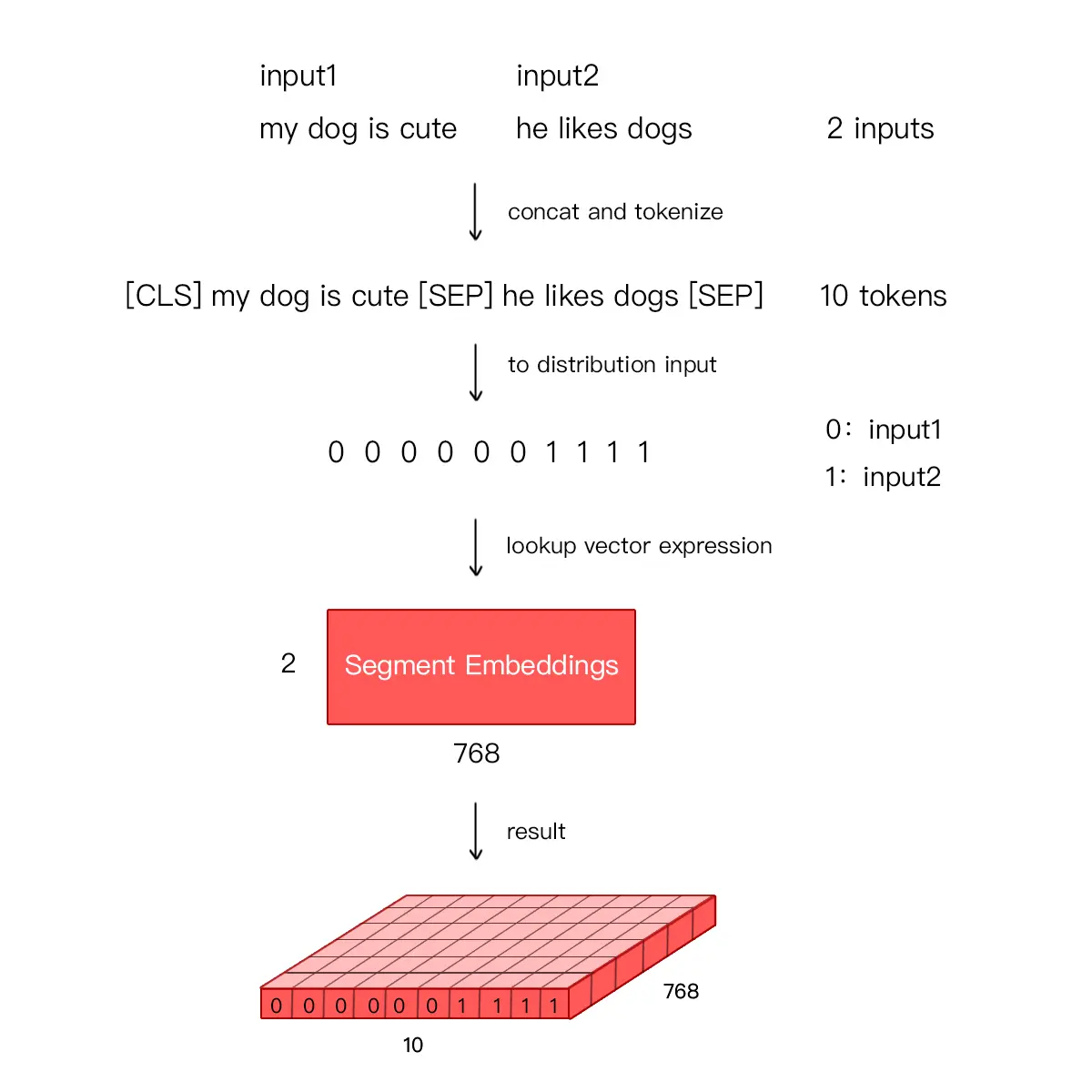
Bert 能够处理句子对的分类任务,这类任务就是判断两个文本是否是语义相似的。句子对中的两个句子被简单的拼接在一起后送入模型中,Bert 如何区分一个句子对是两个句子呢?答案就是 Segment Embeddings。
Segement Embeddings 层有两种向量表示,前一个向量是把 0 赋值给第一个句子的各个 Token,后一个向量是把1赋值给各个 Token,问答系统等任务要预测下一句,因此输入是有关联的句子。而文本分类只有一个句子,那么 Segement embeddings 就全部是 0。
Position Embedding
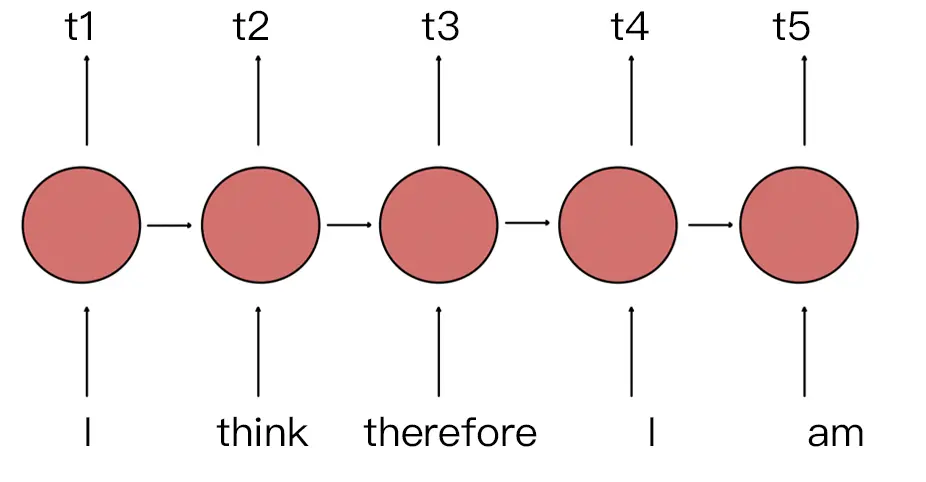
由于出现在文本不同位置的字/词所携带的语义信息存在差异(如 ”你爱我“ 和 ”我爱你“),你和我虽然都和爱字很接近,但是位置不同,表示的含义不同。
在 RNN 中,第二个 ”I“ 和 第一个 ”I“ 表达的意义不一样,因为它们的隐状态不一样。对第二个 ”I“ 来说,隐状态经过 ”I think therefore“ 三个词,包含了前面三个词的信息,而第一个 ”I“ 只是一个初始值。因此,RNN 的隐状态保证在不同位置上相同的词有不同的输出向量表示。
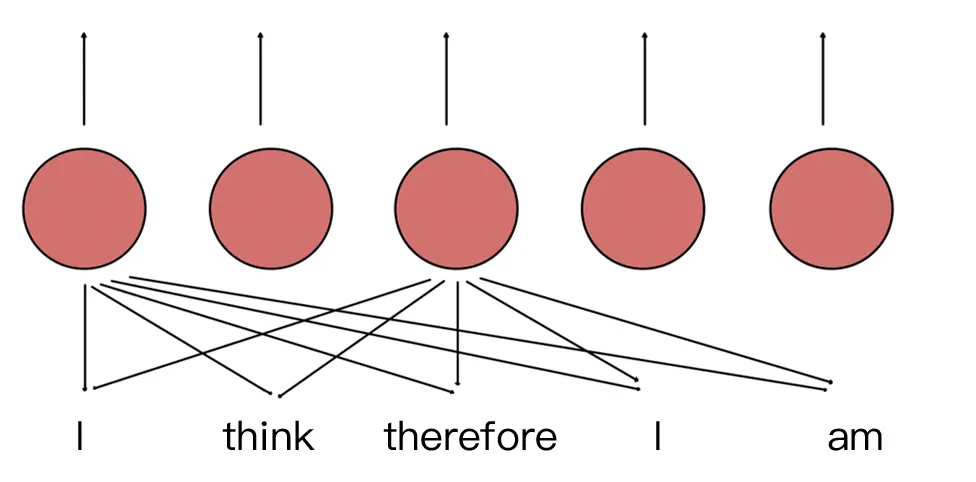
RNN 能够让模型隐式的编码序列的顺序信息,相比之下,Transformer 的自注意力层 (Self-Attention) 对不同位置出现相同词给出的是同样的输出向量表示。尽管 Transformer 中两个 ”I“ 在不同的位置上,但是表示的向量是相同的。
Transformer 中通过植入关于 Token 的相对位置或者绝对位置信息来表示序列的顺序信息。作者测试用学习的方法来得到 Position Embeddings,最终发现固定位置和相对位置效果差不多,所以最后用的是固定位置的,而正弦可以处理更长的 Sequence,且可以用前面位置的值线性表示后面的位置。
偶数位置,使用正弦编码,奇数位置,使用余弦编码。
\[\begin{aligned} P E_{(p o s, 2 i)} & =\sin \left(p o s / 10000^{2 i / d_{\text {model }}}\right) \\ P E_{(p o s, 2 i+1)} & =\cos \left(p o s / 10000^{2 i / d_{\text {model }}}\right) \end{aligned}\]\[\begin{aligned} & \sin (\alpha+\beta)=\sin \alpha \cos \beta+\cos \alpha \sin \beta \\ & \cos (\alpha+\beta)=\cos \alpha \cos \beta-\sin \alpha \sin \beta \end{aligned}\]
Bert 中处理的最长序列是 512 个 Token,长度超过 512 会被截取,Bert 在各个位置上学习一个向量来表示序列顺序的信息编码进来,这意味着 Position Embeddings 实际上是一个 (512, 768) 的 lookup 表,表第一行是代表第一个序列的每个位置,第二行代表序列第二个位置。
最后,Bert 模型将 Token Embeddings (1, n, 768) + Segment Embeddings(1, n, 768) + Position Embeddings(1, n, 768) 求和的方式得到一个 Embedding(1, n, 768) 作为模型的输入。
2.5 Bert 模型参数
Bert 是一个多层的、双向的Transformer编码器。BERT调整了Transformer的三个参数:L(Transformer块的个数)、H(隐藏层维数)、A(自注意力机制的多头的头的数目)。
$B E R T_{B A S E}: L=12, H=768, A=12$, Total Parameters $=110 M$
$B E R T_{L A R G E}: L=24, H=1024, A=16$, Total Parameters $=340 M$
可学习参数主要分为两块:嵌入层、Transformer块,过程有图简述之:
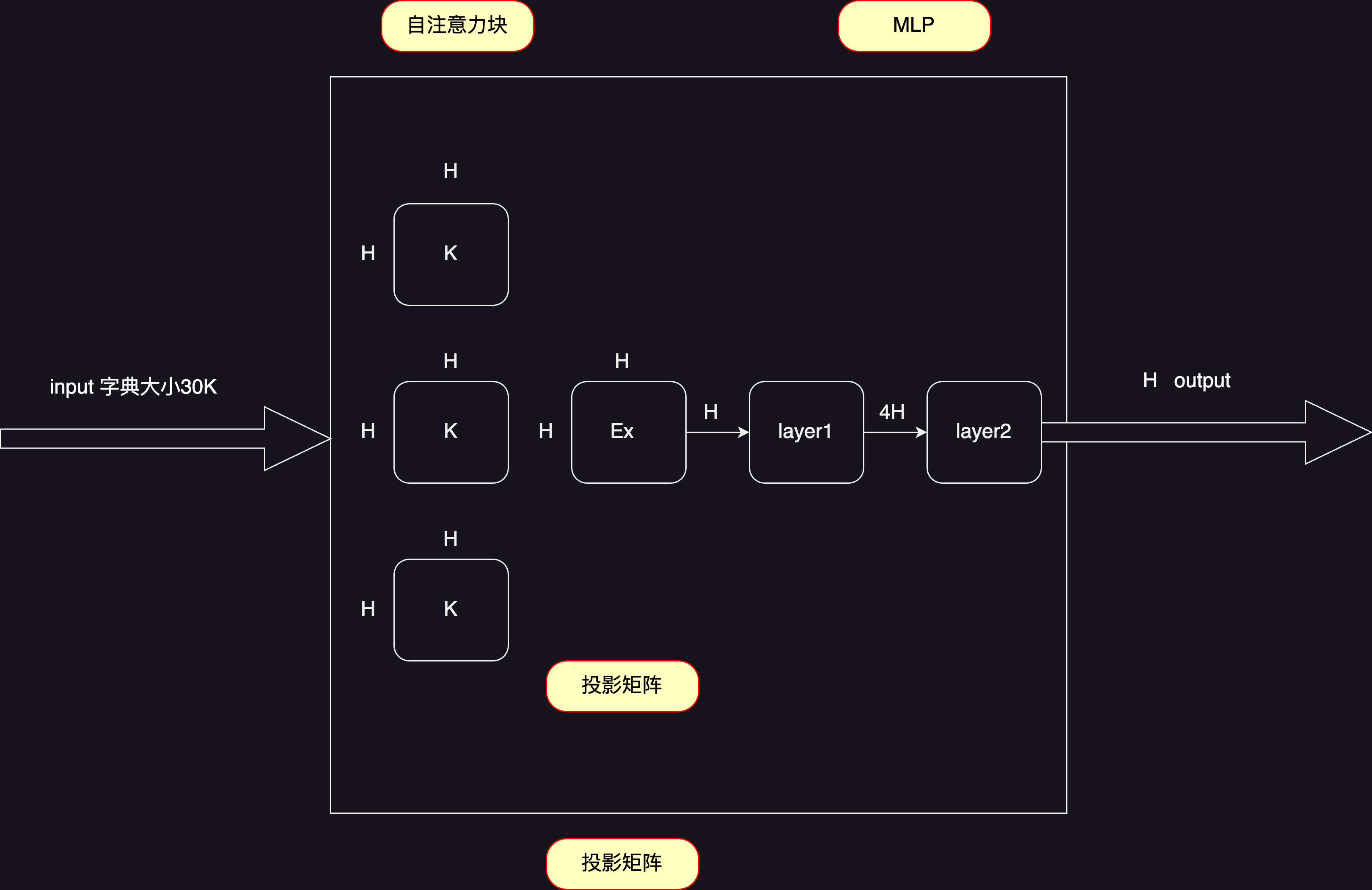
自注意力机制本身并没有可学习参数, 但是对于多头注意力, 会把进入的所有K(Key)、V(Value)、Q(Query)都做一次投影,每次投影的维度为 64 , 而且有 $A \times 64=H$;
如上,前面的自注意力块有 $4 H^2$ 个参数, MLP有 $H \times 4 H \times 2=8 H^2$ 个参数, 则每个Transformer块中有 $12 H^2$ 个参数;
最后再乘 字典大小 和 $L$ , 得到 $S u m=30000 H+12 L H^2$,代入 $B E R T_{B A S E}$ 可以获得确实是大约 $110 M$ 个参数。
3. Bert fine-tuning
BERT模型初始化权重为预训练过程中得到的权重。所有的权重,在微调的过程中都会参与训练,并且用的是有标号的数据,使其更好的适用于下游任务。如对于分类问题在语言模型基础上加一层 softmax 网络,然后再新的预料上重新训练进行 fine-tune。
基于预训练得到的模型,在每个后续的下游任务中都会训练出适用于当前任务的模型。
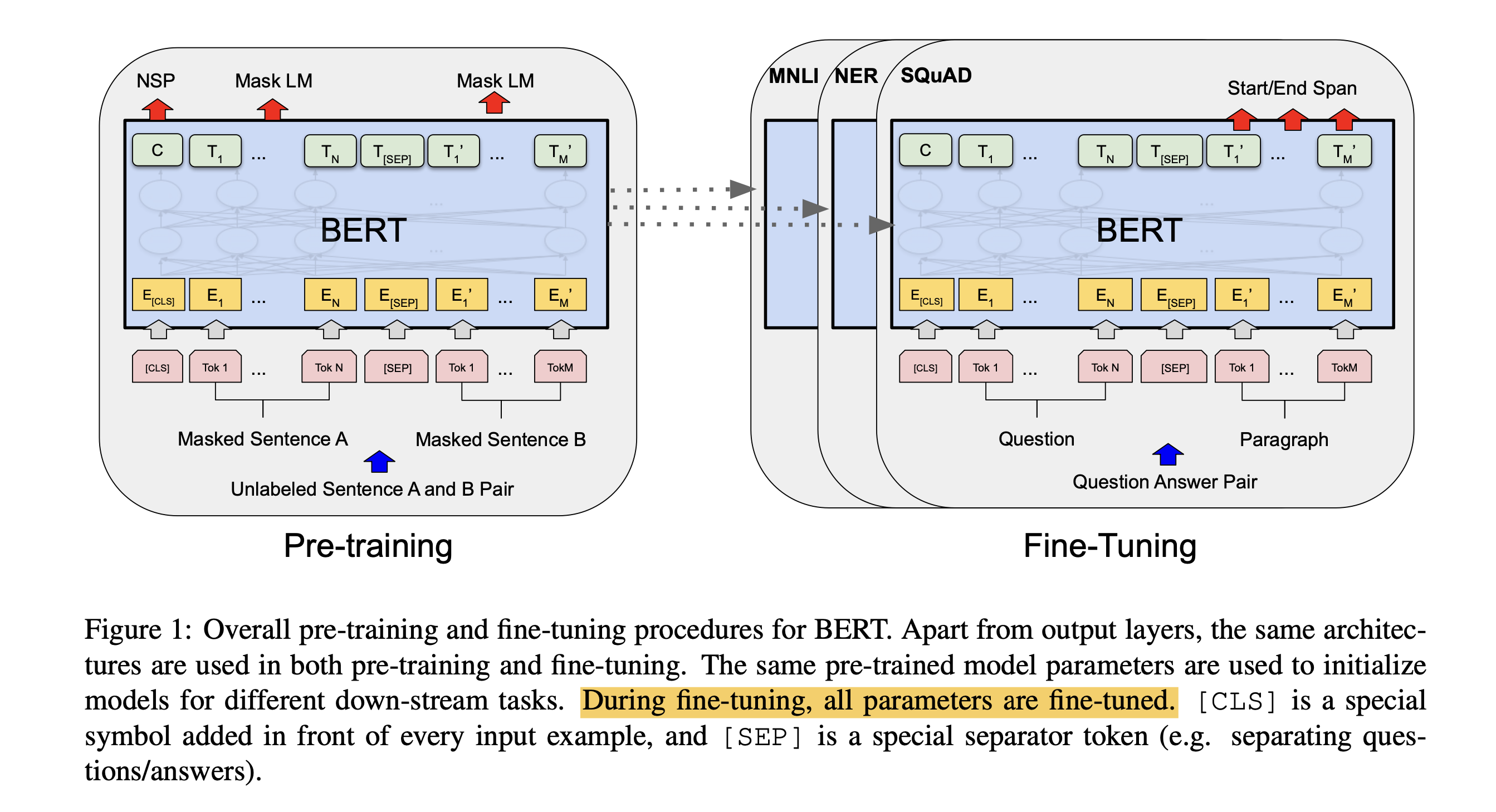
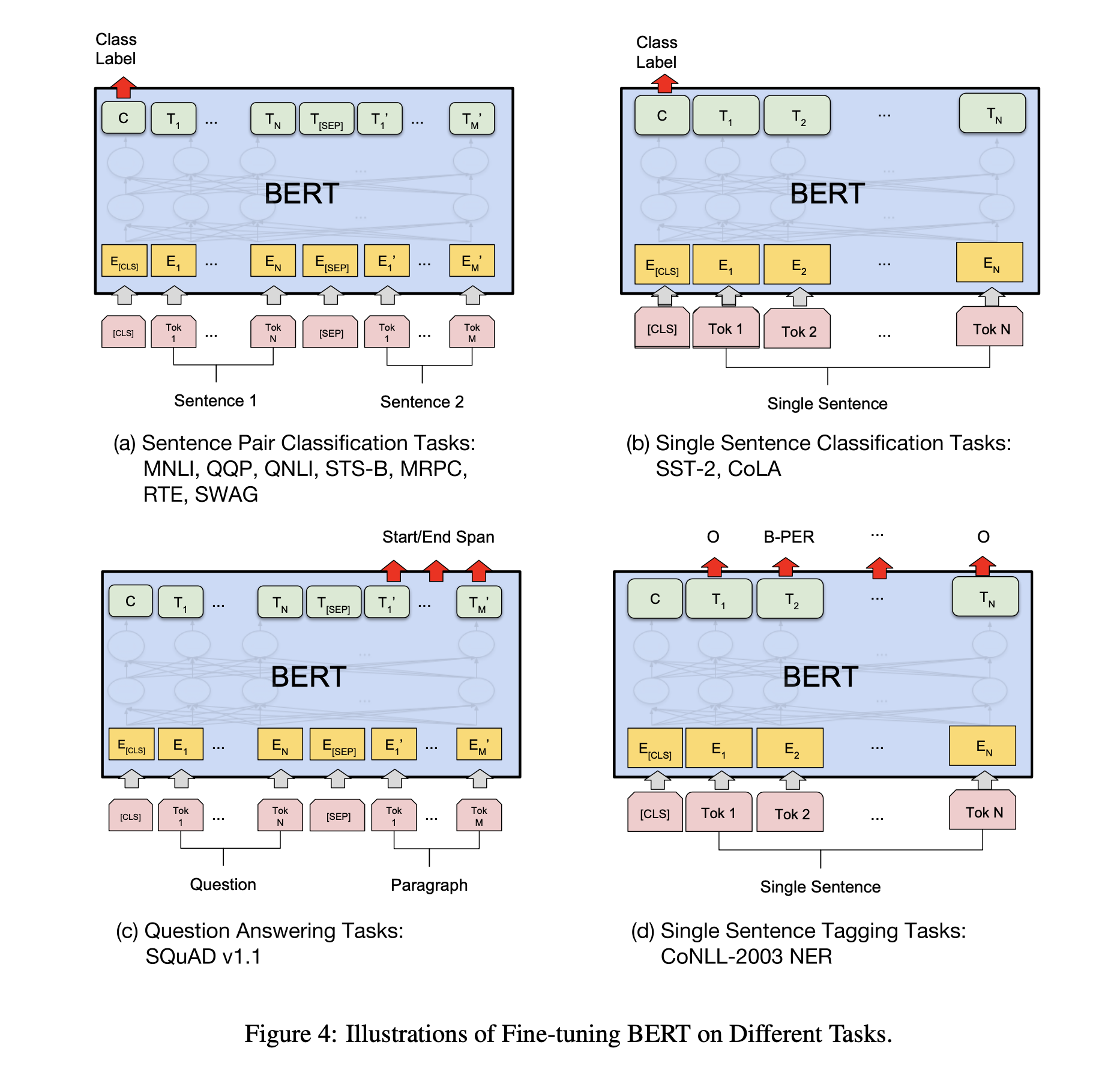
这里fine-tuning之前对模型的修改非常简单,例如针对sequence-level classification problem(例如情感分析),取第一个token的输出表示,喂给一个softmax层得到分类结果输出;对于token-level classification(例如NER),取所有token的最后层transformer输出,喂给softmax层做分类。
总之不同类型的任务需要对模型做不同的修改,但是修改都是非常简单的,最多加一层神经网络即可。如下图所示
BERT 经过微小的改造(增加一个小小的层),就可以用于各种各样的语言任务。
(b)与 Next Sentence Prediction类似,通过在 「[CLS]」 标记的 Transformer 输出顶部添加分类层,完成诸如情感分析之类的「分类」任务。
(c)在问答任务(例如 SQuAD v1.1)中,会收到一个关于文本序列的问题,并需要在序列中标记答案。使用 BERT,可以通过学习标记答案开始和结束的两个额外向量来训练问答模型。
(d)在命名实体识别 (NER) 中,接收文本序列,并需要标记文本中出现的各种类型的实体(人、组织、日期等)。使用 BERT,可以通过将每个标记的输出向量输入到预测 NER 标签的分类层来训练 NER 模型。
4. Bert 代码实现
4.1 Masked token
# MASK LM
n_pred = min(max_pred, max(1, int(round(len(input_ids) * 0.15)))) # 15 % of tokens in one sentence
cand_maked_pos = [i for i, token in enumerate(input_ids)
if token != word_dict['[CLS]'] and token != word_dict['[SEP]']]
shuffle(cand_maked_pos)
masked_tokens, masked_pos = [], []
for pos in cand_maked_pos[:n_pred]:
masked_pos.append(pos)
masked_tokens.append(input_ids[pos])
if random() < 0.8: # 80%
input_ids[pos] = word_dict['[MASK]'] # make mask
elif random() < 0.5: # 10%
index = randint(0, vocab_size - 1) # random index in vocabulary
input_ids[pos] = word_dict[number_dict[index]] # replace
4.2 Next Sentence
if tokens_a_index + 1 == tokens_b_index and positive < batch_size/2:
# 如果tokens_a_index+1等于tokens_b_index,且positive小于batch_size的一半,
# 则将[input_ids, segment_ids, masked_tokens, masked_pos, True]添加到batch中
batch.append([input_ids, segment_ids, masked_tokens, masked_pos, True]) # IsNext
positive += 1
elif tokens_a_index + 1 != tokens_b_index and negative < batch_size/2:
# 如果tokens_a_index+1不等于tokens_b_index,且negative小于batch_size的一半,
# 则将[input_ids, segment_ids, masked_tokens, masked_pos, False]添加到batch中
batch.append([input_ids, segment_ids, masked_tokens, masked_pos, False]) # NotNext
negative += 1
4.3 ScaledDotProductAttention
def forward(self, Q, K, V, attn_mask): ## self attention 操作
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size x n_heads x len_q(=len_k) x len_k(=len_q)]
scores.masked_fill_(attn_mask, -1e9) #,注意把 padding部分的注意力去掉
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
4.4 MultiHeadAttention
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads)
self.W_K = nn.Linear(d_model, d_k * n_heads)
self.W_V = nn.Linear(d_model, d_v * n_heads)
def forward(self, Q, K, V, attn_mask):
# q: [batch_size x len_q x d_model], k: [batch_size x len_k x d_model], v: [batch_size x len_k x d_model]
residual, batch_size = Q, Q.size(0)
# (B, S, D) -proj-> (B, S, D) -split-> (B, S, H, W) -trans-> (B, H, S, W)
q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k]
k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k]
v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v]
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size x n_heads x len_q x len_k]
# context: [batch_size x n_heads x len_q x d_v], attn: [batch_size x n_heads x len_q(=len_k) x len_k(=len_q)]
context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)
context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) # context: [batch_size x len_q x n_heads * d_v]
output = nn.Linear(n_heads * d_v, d_model)(context)
return nn.LayerNorm(d_model)(output + residual), attn # output: [batch_size x len_q x d_model]
4.5 BERT
class PoswiseFeedForwardNet(nn.Module):
# 定义前馈神经网络
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
def forward(self, x):
# (batch_size, len_seq, d_model) -> (batch_size, len_seq, d_ff) -> (batch_size, len_seq, d_model)
return self.fc2(gelu(self.fc1(x)))
class EncoderLayer(nn.Module):
# 定义编码层
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, enc_inputs, enc_self_attn_mask):
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) # enc_inputs to same Q,K,V
enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size x len_q x d_model]
return enc_outputs, attn
class BERT(nn.Module):
# 定义BERT模型
# 包含一个嵌入层 embedding,多个编码层 layers,一个全连接层 fc,
# 两个激活函数 activ1 和 activ2,一个层归一化 norm,一个分类器 classifier,和一个解码器 decoder。
def __init__(self):
super(BERT, self).__init__()
self.embedding = Embedding()
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
self.fc = nn.Linear(d_model, d_model)
self.activ1 = nn.Tanh()
self.linear = nn.Linear(d_model, d_model)
self.activ2 = gelu
self.norm = nn.LayerNorm(d_model)
self.classifier = nn.Linear(d_model, 2)
# decoder is shared with embedding layer
embed_weight = self.embedding.tok_embed.weight
n_vocab, n_dim = embed_weight.size()
self.decoder = nn.Linear(n_dim, n_vocab, bias=False)
self.decoder.weight = embed_weight
self.decoder_bias = nn.Parameter(torch.zeros(n_vocab))
def forward(self, input_ids, segment_ids, masked_pos):
output = self.embedding(input_ids, segment_ids)
enc_self_attn_mask = get_attn_pad_mask(input_ids, input_ids)
for layer in self.layers:
output, enc_self_attn = layer(output, enc_self_attn_mask)
# output : [batch_size, len, d_model], attn : [batch_size, n_heads, d_mode, d_model]
# it will be decided by first token(CLS)
h_pooled = self.activ1(self.fc(output[:, 0])) # [batch_size, d_model]
logits_clsf = self.classifier(h_pooled) # [batch_size, 2]
masked_pos = masked_pos[:, :, None].expand(-1, -1, output.size(-1)) # [batch_size, maxlen, d_model]
h_masked = torch.gather(output, 1, masked_pos) # masking position [batch_size, len, d_model]
h_masked = self.norm(self.activ2(self.linear(h_masked)))
logits_lm = self.decoder(h_masked) + self.decoder_bias # [batch_size, maxlen, n_vocab]
return logits_lm, logits_clsf
文档信息
- 本文作者:huzixia
- 本文链接:https://huzixia.github.io/2024/02/23/bert/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)