
sora技术文档,主要包括视频生成模型作为世界模拟器,1. 将视觉数据转换为统一表示方法,2. 模型的训练,3. 模型评估。Sora 和之前 Runway在架构上的区别。
#! https://zhuanlan.zhihu.com/p/682581952
sora技术文档
openai 论文:Video generation models as world simulators 链接:https://openai.com/research/video-generation-models-as-world-simulators
Google 论文:Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution 链接:https://arxiv.org/pdf/2307.06304.pdf
Meta 论文:Scalable Diffusion Models with Transformers 链接:https://arxiv.org/pdf/2212.09748.pdf
Video generation models as world simulators
视频生成模型作为世界模拟器
OpenAI 认为,scaling 视频生成模型是构建通用物理世界模拟器的有希望的路径。
Sora 是一种对视觉数据进行广义建模的模型,它可以生成跨越不同持续时间、宽高比和分辨率的视频和图像,高清视频的长度可达一分钟。 具体的方法分为三个阶段:
- 将视觉数据转换为统一的表示方法
- 模型的训练(但这一部分OpenAI没有在报告中说明,只简略提到了模型架构)
- 模型评估
1. 将视觉数据转换为统一表示方法
OpenAI将「统一表示方法」分为了三个部分:将视觉数据转化为 patches、视频压缩网络、 时空潜在 patches 。
- 将视觉数据转化为 patches :LLMs 使用文本 tokens ,而 Sora 使用视觉 patches ;patches 是一种高度可扩展且有效的表示形式,适用于训练各种类型的视频和图像的生成模型。在高层次上,OpenAI 通过首先将视频压缩成低维潜空间,然后将表示分解成时空 patches 来处理视频。
- 视频压缩网络:OpenAI训练了一个视频压缩网络,以降低视觉数据的维度。这个网络以原始视频作为输入,并输出一个在时间和空间上都被压缩的潜在表示。Sora在这个压缩的潜在空间中进行训练,并生成视频。OpenAI 还训练了一个相应的解码器模型,将生成的潜在表示映射回像素空间。
- 时空潜在 patches:给定一个压缩的输入视频,OpenAI 提取一系列时空patches,它们作为 transformer tokens。这个方案也适用于图像,因为图像只是具有单个帧的视频。OpenAI 基于 patches 的表示使得Sora能够在分辨率、持续时间和宽高比可变的视频和图像上进行训练。在推理时,OpenAI 可以通过将随机初始化的 patches 排列在适当大小的网格中来控制生成视频的大小。
2. 模型的训练
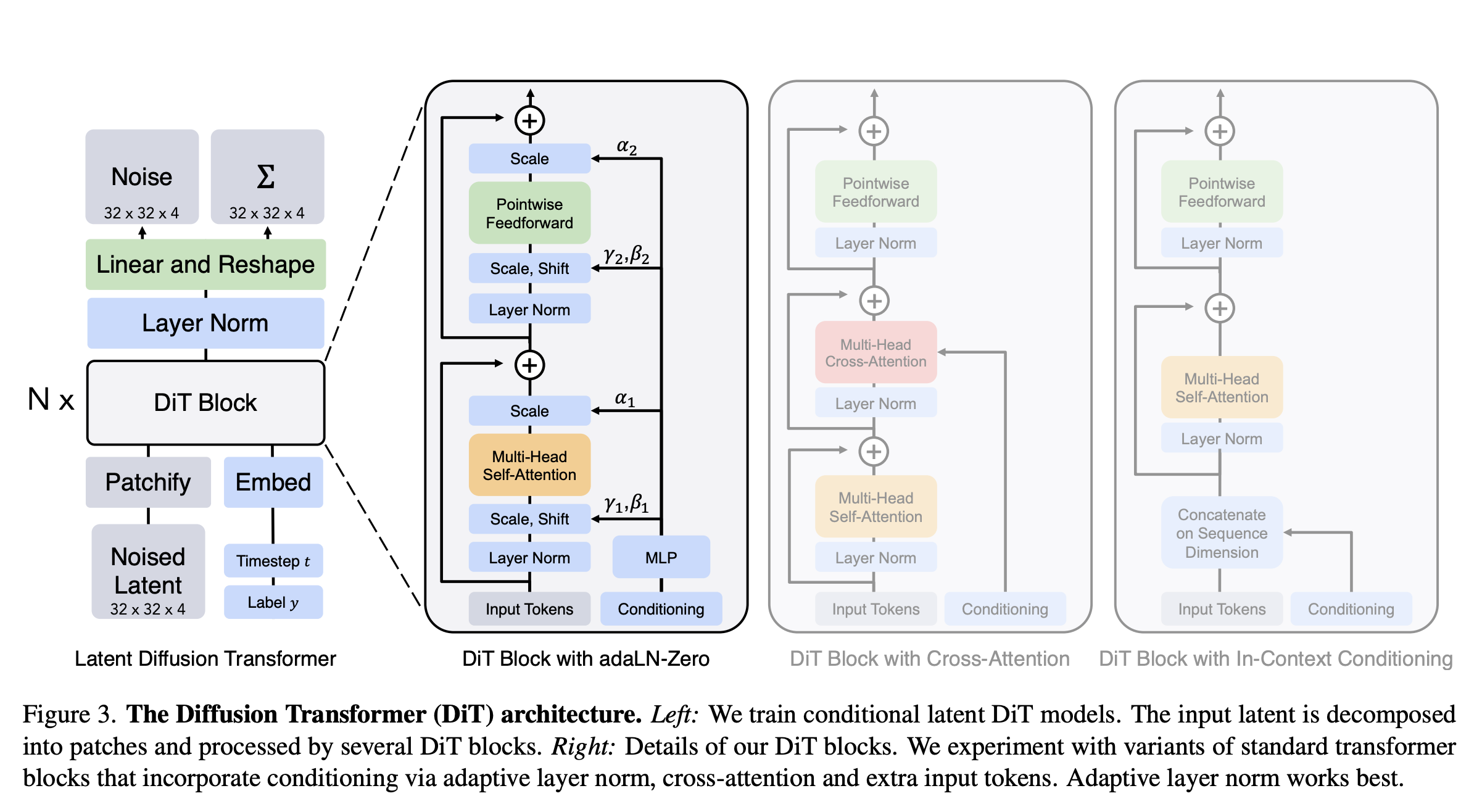
模型架构方面:Sora 是一个扩散模型,给定输入的噪声patches(以及像文本提示这样的条件信息),它被训练成预测原始的“干净”patches。重要的是,Sora是一个扩散Transformer。
3. 模型评估
Sora 的一些能力:时长、分辨率、画面比例可变;语言理解能力;可通过图像和视频进行提示;图像生成能力;涌现能力。
时长、分辨率、画面比例可变:Sora可以采样横屏1920x1080p视频、竖屏1080x1920视频以及两者之间的所有内容。这使得Sora可以直接以原生宽高比为不同设备创建内容。并且,以原生宽高比训练视频可以改善构图和取景。
语言理解能力:OpenAI 首先训练一个高度描述性的字幕模型,然后使用它为训练集的所有视频生成文本字幕。训练高度描述性的视频字幕可以提高文本的准确性以及视频的整体质量。另外,还利用 GPT 将用户简短的提示转化为更详细的描述,并发送给视频模型。这使得 Sora 能够更准确地按照用户的提示进行操作。
可通过图像和视频进行提示: Sora 不仅可以使用文本作为提示词,还可以接受图片或视频作为提示,并执行各种图像和视频编辑任务,例如创建循环的视频,给静态图像添加动画效果,将视频向前或向后扩展、视频对视频的风格转换、视频之间的无缝过渡等等。
图像生成能力:通过在一个帧的时间范围内,将高斯噪声 patches 排列在一个空间网格中来实现这一点。可以生成不同尺寸的图像,最高分辨率可达2048x2048。
- 涌现能力:3D一致性;长视频的时间一致性;与世界互动;模拟数字世界。
- 3D一致性:Sora 可以生成具有动态摄像机运动的视频。随着摄像机的移动和旋转,人物和场景元素在三维空间中保持一致移动。
- 长视频的时间一致性:Sora 通常能够有效地建模短程和长程的依赖关系,尽管并非总是如此。例如,Sora 可以在人、动物和物体被遮挡或离开画面时仍然保持它们的存在。同样,它可以在一个样本中生成同一角色的多个镜头,并在整个视频中保持它们的外观。
- 与世界互动:Sora 有时可以模拟对世界状态产生简单影响的动作。例如,画家可以在画布上留下持续一段时间的新笔触,或者一个人可以吃掉一个汉堡并留下咬痕。
- 模拟数字世界:Sora 还能够模拟人工过程,一个例子就是视频游戏。Sora 可以同时使用基本策略控制Minecraft中的玩家,同时以高保真度渲染世界及其动态。通过提示Sora 提到“Minecraft”的标题,可以激发这些能力。
- 一些限制:Sora 无法准确模拟许多基本交互的物理效应,比如玻璃破碎。其他交互,比如吃东西,也不总是能正确地改变物体状态,以及在长时间样本中出现的不连贯性或物体的突然出现等等。
Sora 和之前 Runway在架构上的区别
简单来说 Runway 是基于扩散模型(Diffusion Model)的,而 Sora 是基于 Diffusion Transformer。
Runway、Stable Diffusion 是基于扩散模型(Diffusion Model),扩散模型(Diffusion Model)的训练过程是通过多个步骤逐渐向图片增加噪点,直到图片变成完全无结构的噪点图片,然后在生成图片的时候,基于一张完全噪点的图片,逐步减少噪点,直到还原出一张清晰的图片。
- 文本模型像 GPT-4 则是 Transformer 模型。Transformer 则是一套编码器和解码器的架构,将文本编码成数字向量,然后解码的时候从数字向量还原出文本。
- Sora 则是一个融合了两者的 Diffusion Transformer 模型。通过 Transformer 的编码器 - 解码器架构处理含噪点的输入图像,并在每一步预测出更清晰的图像版本。编码器负责对含噪点的输入进行编码,而解码器则负责生成更清晰图像的预测。
GPT-4 被训练以处理一串 Token,并预测出下一个 Token。Sora 不是预测序列中的下一个文本,而是预测序列中的下一个“Patch”。
在文本预测生成中,基本单位是 Token,Token 很好理解,就是一个单词或者单词的一部分。Patch 的概念相对不那么好理解,不过今天看到一篇文章,作者举了个很好的例子。
- 想象一下《黑暗骑士》的电影胶片,将一卷胶片绕在一个金属盘上,然后挂在一个老式电影院的投影机上。
- 你把电影胶卷从盘中展开,然后剪下最前面的 100 帧。你挑出每一帧——这里是小丑疯狂大笑,那里是蝙蝠侠痛苦的表情——并进行以下不同寻常的操作:
- 你拿起一把 X-acto 精细刻刀,在第一帧电影胶片上剪出一个变形虫状的图案。你像处理精密仪器一样小心翼翼地用镊子提取这片形似变形虫的胶片,然后安全地保存起来。之后,你处理下一帧:在接下来的胶片上切出同样位置、同样形状的变形虫图案。你再次用镊子小心地取出这个新的变形虫形状的胶片——形状与前一个完全相同——并将其精确地放置在第一个之上。你这样做,直到完成所有的 100 帧。
- 你现在有了一个色彩斑斓的变形虫,沿着 Y 轴扩展。这是一座可以通过投影机播放《黑暗骑士》的小片段的胶片塔,就好像有人在投影机前握着拳头,只让电影的一小部分影像从拳心通过。
- 然后,这座胶片塔被压缩并转化为所谓的“Patch”——一种随时间变化的色块。
Patch 的创新之处——以及 Sora 之所以显得如此强大——在于它们让 OpenAI 能够在大量的图像和视频数据上训练 Sora。想象一下从每一个存在的视频中剪出的 Patch——无尽的胶片塔——被堆叠起来并输入到模型中。
以前的文本转视频方法需要训练时使用的所有图片和视频都要有相同的大小,这就需要大量的预处理工作来裁剪视频至适当的大小。但是,由于 Sora 是基于“Patch”而非视频的全帧进行训练的,它可以处理任何大小的视频或图片,无需进行裁剪。
因此,可以有更多的数据用于训练,得到的输出质量也会更高。例如,将视频预处理至新的长宽比通常会导致视频的原始构图丢失。一个在宽屏中心呈现人物的视频,裁剪后可能只能部分展示该人物。因为 Sora 能接收任何视频作为训练输入,所以其输出不会受到训练输入构图不良的影响。
在结合前面提到的 Diffusion Transformer 架构,OpenAI 可以在训练 Sora 时倾注更多的数据和计算资源,从而得到令人惊叹的效果。
另外 Sora 刚发布视频时,能模拟出咖啡在杯子里溅出的液体动力学,以至于有人以为是连接了游戏引擎,但实际上 Sora 还是基于生成式模型,这是因为 Sora 在训练时,使用了大量的视频数据,这些视频中包含了大量的物理规则,所以 Sora 能够模拟出液体动力学。这类似于 GPT-4 在训练时,使用了大量的代码来作为训练数据,所以 GPT-4 能够生成代码。
所以数据为王,再次验证了,数据和特征是上限,而模型和算法只是逼近这个上限而已。
The Diffusion Transformer (DiT) architecture
文档信息
- 本文作者:huzixia
- 本文链接:https://huzixia.github.io/2024/02/18/sora-simple/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)